

Table of Contents
Classification, Detection, Segmentation
컴퓨터 비전에서 자주 다루는 태스크를 크게 세 가지로 분류해볼 수 있다.
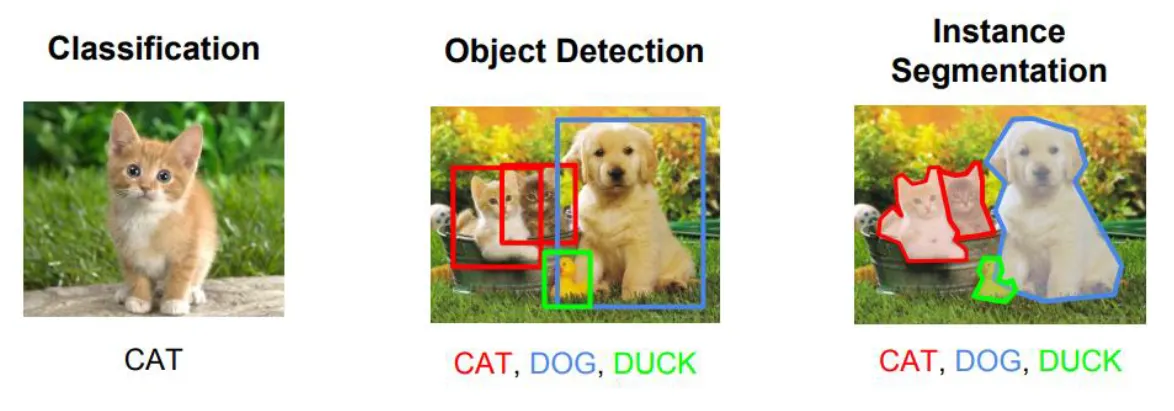
•
Classification은 단순한 이미지 분류. 이미지가 어떤 클래스인지 판별한다.
•
Object Detection은 객체 검출을 말한다. Classification보다는 좀 더 고차원의 Task라고 볼 수 있다. 이미지 속에 어떠한 Class가 어디에 위치해 있는지까지 판별.
•
Instance Segmentation은 Object Detection에서 박스(Bounding box)로 구별하는 대신 Segmentation까지 수행해야 한다. 픽셀별로 어떤 카테고리에 속하는지, 어느 Instance인지 구분할 수 있어야 한다. (Cat 1인지 Cat 2인지 등등...)
대표적인 딥러닝 모델들
사실 위에서 설명한 태스크들은 꼭 딥러닝이 아니더라도, 이미지 프로세싱 분야의 전통적인 방법으로도 연구되어온 알고리즘들이나 메소드들이 많다. 상황에 따라, 꼭 딥러닝을 수행해야 하는 것은 아니다. 딥러닝만이 무조건 답이 아니라는 것을 꼭 짚고 넘어가면 좋겠다.
•
Classification
◦
CNN을 필두로 한 모델들이 대부분이다.
◦
LeNet, AlexNet.
◦
Inception 구조를 가지는 GoogleNet
◦
VGGNet, ResNet.
•
Object Detection
◦
2 Step Models (Two-Shot Method): R-CNN 계열 모델들(R-CNN, Fast R-CNN, Faster R-CNN, SPPNet, ...)이 이에 해당한다. Region Proposal 과정이 수반된다.
◦
1 Step Models (Unified Detection, Single-Shot Method): 대표적으로 YOLO와 SSD가 이에 해당한다. Region Proposal을 아예 거치지 않고 Detection을 수행한다.
공부 순서
나는 아래 순서대로 공부했지만, 이것이 꼭 절대적인 공부 순서는 아니다.
•
Classification
◦
VGGnet → Googlenet → Resnet → Inceptionv3 → Densenet → WRN → MobileNet → ResNext
•
Object Detection
◦
R-CNN → (SPPNet) → Fast-RCNN → Faster-RCNN → YOLO v1 → SSD → FPN
