
주로 이진 분류에서 성능 평가 지표로 사용하는 5가지 수치에 대해 알아보자.
Table of Contents
Accuracy(정확도)
Accuracy는 실제 데이터에서 예측 데이터가 얼마나 같은지를 판단하는 단순한 지표이다.
한계
하지만 이진 분류의 경우, 데이터의 구성에 따라 모델의 성능을 왜곡할 수 있기 때문에 정확도 수치 하나만 가지고 성능을 평가하지 않는다. 특히 정확도는 불균형한 레이블 값 분포에서 분류 모델의 성능을 판단할 경우, 적합한 평가 지표가 아니다.
예를 들어 100개의 데이터가 있고 이 중에 90개의 데이터 레이블이 0, 단 10개의 데이터 레이블이 1이라고 한다면, 무조건 0으로 예측 결과를 찍어도 Accuracy가 90%가 된다. 아무것도 하지 않고 무조건 특정한 결과로 찍어도 높은 정확도 수치가 나타날 수 있다는 것이다.
이렇듯 단순히 Accuracy만으로는 잘못된 평가 결과에 빠질 수 있다. 따라서 이진 분류에서는 정확도보다는 다른 성능 평가 지표가 더 중요시되는 경우가 많다.
Confusion Matrix(오차 행렬)
Confusion Matrix는 이진 분류에서 예측 오류가 얼마인지와 더불어 어떠한 유형의 예측 오류가 발생하고 있는지를 함께 나타내는 지표이다.
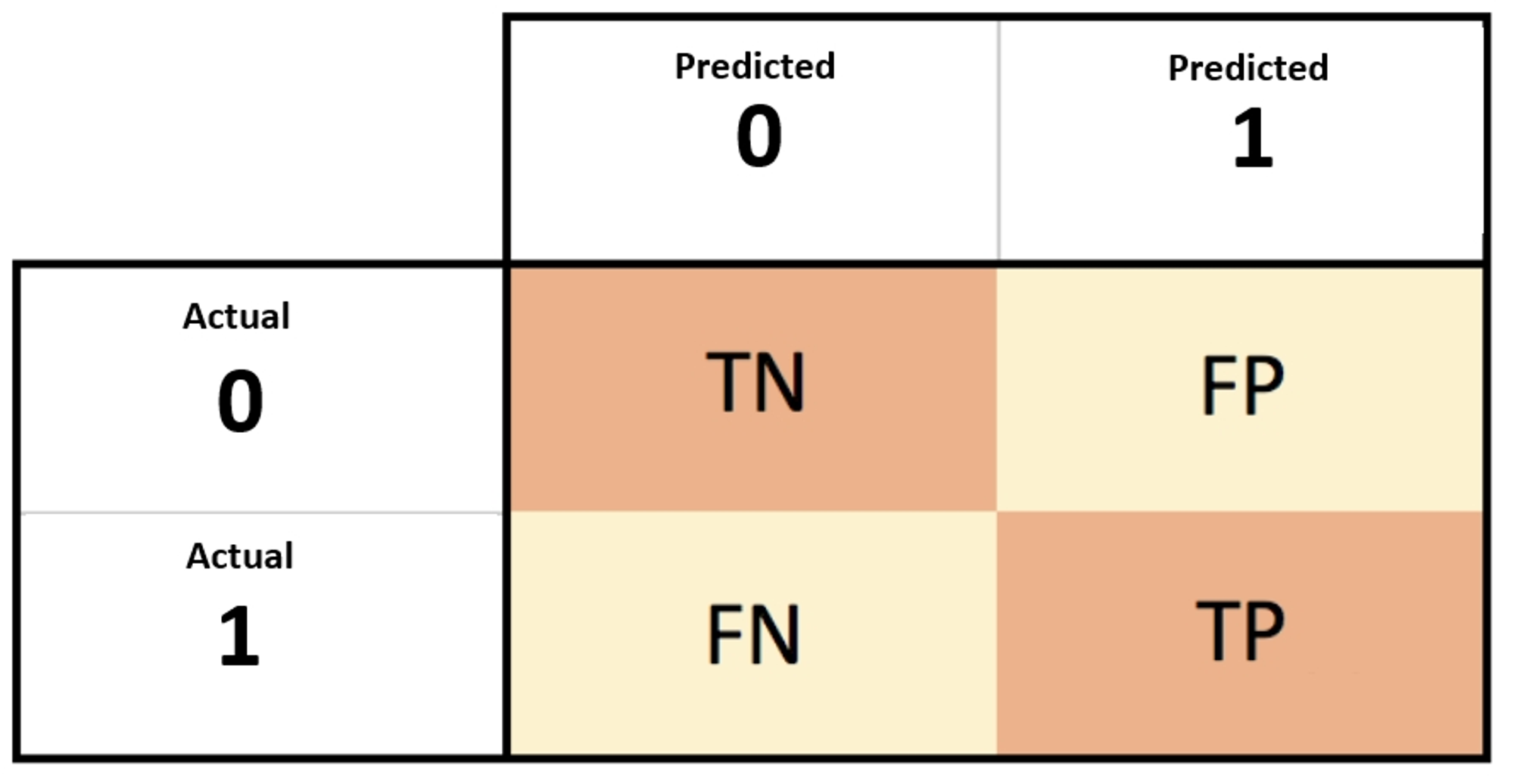

True/False: 실제와 예측이 일치하는가?
Positive/Negative: 뭘로 예측했는가?
•
TN(True Negative, Negative Negative): 실제는 Negative인데, Negative로 예측함.
•
FP(False Positive, Negative Positive): 실제는 Negative인데, Positive로 예측함.
•
FN(False Negative, Positive Negative): 실제는 Positive인데, Negative로 예측함.
•
TP(True Positive, Positive Positive): 실제는 Positive인데, Positive로 예측함.
TN, FP, FN, TP값을 조합해 후술할 주요 지표인 정밀도(Precision), 재현율(Recall)값을 계산할 수 있다. 사실은 정확도도 Confusion matrix를 이용해 재정의할 수 있다.
간단한 예시

•
TN(True Negative, Negative Negative)
◦
실제는 임신이 아니고(0), 임신이 아닌 것(0)으로 잘 예측함.
•
FP(False Positive, Negative Positive)
◦
실제는 임신이 아닌데(0), 임신(1)로 예측함.
•
FN(False Negative, Positive Negative)
◦
실제는 임신인데(1), 임신이 아닌 것(0)으로 예측함.
•
TP(True Positive, Positive Positive)
◦
실제는 임신인데(1), 임신(1)으로 잘 예측함.
어떤 게 Positive고 어떤 게 Negative?
불균형한 레이블 클래스를 가지는 데이터에서는 많은 데이터 중 중점적으로 찾아야 하는 매우 적은 수의 레이블에 1, 그렇지 않은 경우에 0을 부여하는 경우가 많다.
가령 암 검출 Task에서는 암인 경우가 1, 암이 아닌 경우가 0이고, 금융사기 검출 같은 Task에서는 사기인 경우가 1, 정상인 경우가 0인 경우가 일반적이다.
정밀도(Precision), 재현율(Recall)
Precision과 Recall은 각각 다음 공식으로 계산된다.
Precision과 Recall 모두 TP를 높이는 데 동일하게 초점을 맞추지만, Precision은 FP(실제는 0인데 예측은 1)을 낮추는 데에 초점을, Recall은 FN(실제는 1인데 예측 0)을 낮추는 데에 초점을 맞춘다.
이전에 블로그에 쓴 글 중에 Object Detection에서의 Precision, Recall만을 따로 설명한 글이 있습니다. 예시가 필요하신 분들은 읽어보시면 도움이 될 것 같습니다.
Task에 따른 Precision, Recall의 상대적 중요도
보통은 Recall이 Positive보다 상대적으로 중요한 업무가 많지만, Precision이 더 중요한 지표인 경우도 있다.
•
암 검출, 금융사기 검출 같은 Task에서는 실제로 Positive인 얘들을 Negative로 예측하면 큰일난다.
◦
Recall이 중요한 케이스.
•
스팸 검출 같은 Task에서는 실제로 Negative인 얘들을 Positive로 예측하면 큰일난다.
◦
Precision이 중요한 케이스.
어느 한 쪽만 믿으면 안 된다
하지만 이 두 수치만으로는 충분히 숫자놀음이 될 수 있다.
•
Precision 100% 만들기!
◦
"확실한 놈만 팬다" → 확실한 경우에만 Positive로 예측하고, 나머지는 Negative로 예측하면 된다.
◦
전체 환자 1000명 중 확실한 암 징후가 나타나는 환자가 1명뿐이라면, 1명만 Positive로 예측하고 나머지는 모두 Negative로 예측하더라도 FP는 0이므로 Precision은 100%가 된다.
•
Recall 100% 만들기!
◦
"모두 Positive로 예측" → 그냥 모두 Positive로 예측하면 된다.
◦
전체 환자 1000명을 모두 암(Positive)으로 예측해버려도 FN은 0이므로 Recall은 100%가 된다.
이처럼 Precision과 Recall 어느 한 쪽만 참조하면 극단적인 수치 조작이 가능하다. 따라서 Precision과 Recall의 수치가 적절하게 조합된 평가 지표가 필요하다.
Precision/Recall Trade-off
Precision과 Recall은 상호 보완적인 평가 지표이기 때문에 어느 한 쪽을 강제로 높이면 다른 하나의 수치는 떨어지기 쉽다. 이를 Precision/Recall Trade-off라고 부른다.
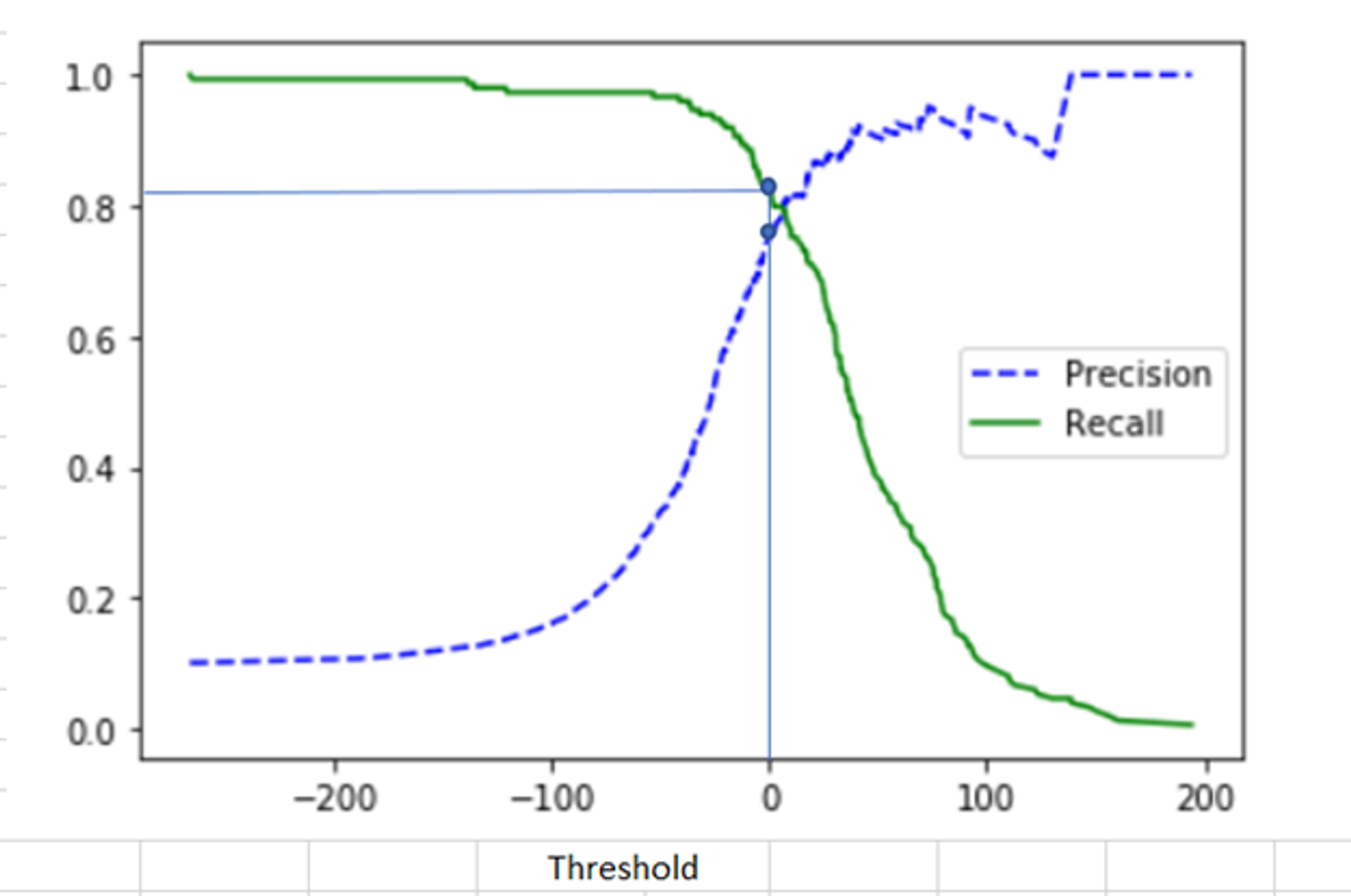
Precision과 Recall의 Trade-off를 결정하는 수치는 분류 결정 Threshold이다. Threshold는 Positive 예측값을 결정하는 확률의 기준이 된다. 보통 이진 분류의 경우 확률이 0.5 초과면 Positive로, 0.5 이하면 Negative로 예측하는데, 이 0.5 값이 바로 Threshold이다.
•
Threshold를 낮추면, Positive로 예측하는 값이 더 많아지게 되니 Precision은 감소하고, Recall은 증가한다.
•
Threshold를 높이면, Positive로 예측하는 값이 더 적어지게 되니 Precision은 증가하고, Recall은 감소한다.
F1 Score
F1 Score는 Precision과 Recall을 결합한 지표이다. Precision과 Recall이 어느 한 쪽으로 치우치지 않을 때 상대적으로 높은 값을 가진다.
ROC Curve, AUC Score
ROC Curve
ROC Curve와 이에 기반한 AUC Score는 이진 분류의 예측 성능 측정에서 중요하게 사용되는 지표이다.
ROC Curve는 FPR(False Positive Rate)이 변할 때 TPR(True Positive Rate)이 어떻게 변하는지를 나타내는 곡선이다. FPR을 X축으로, TPR을 Y축으로 잡은 그래프이다.
•
TPR은 민감도라고 불린다. 실제 값 Positive가 정확히 예측되어야 하는 수준을 나타낸다.
◦
이는 Recall과 정의가 같다. 따라서 TPR은 다음 수식으로 구할 수 있다.
•
FPR은 1-TNR인데, 먼저 TNR을 알아보자.
◦
TNR은 특이성으로 불린다. 실제 값 Negative가 정확히 예측되어야 하는 수준을 나타낸다.
▪
TNR은 다음 수식으로 구할 수 있다.
◦
따라서 FPR은 다음 수식으로 구할 수 있다.
예시
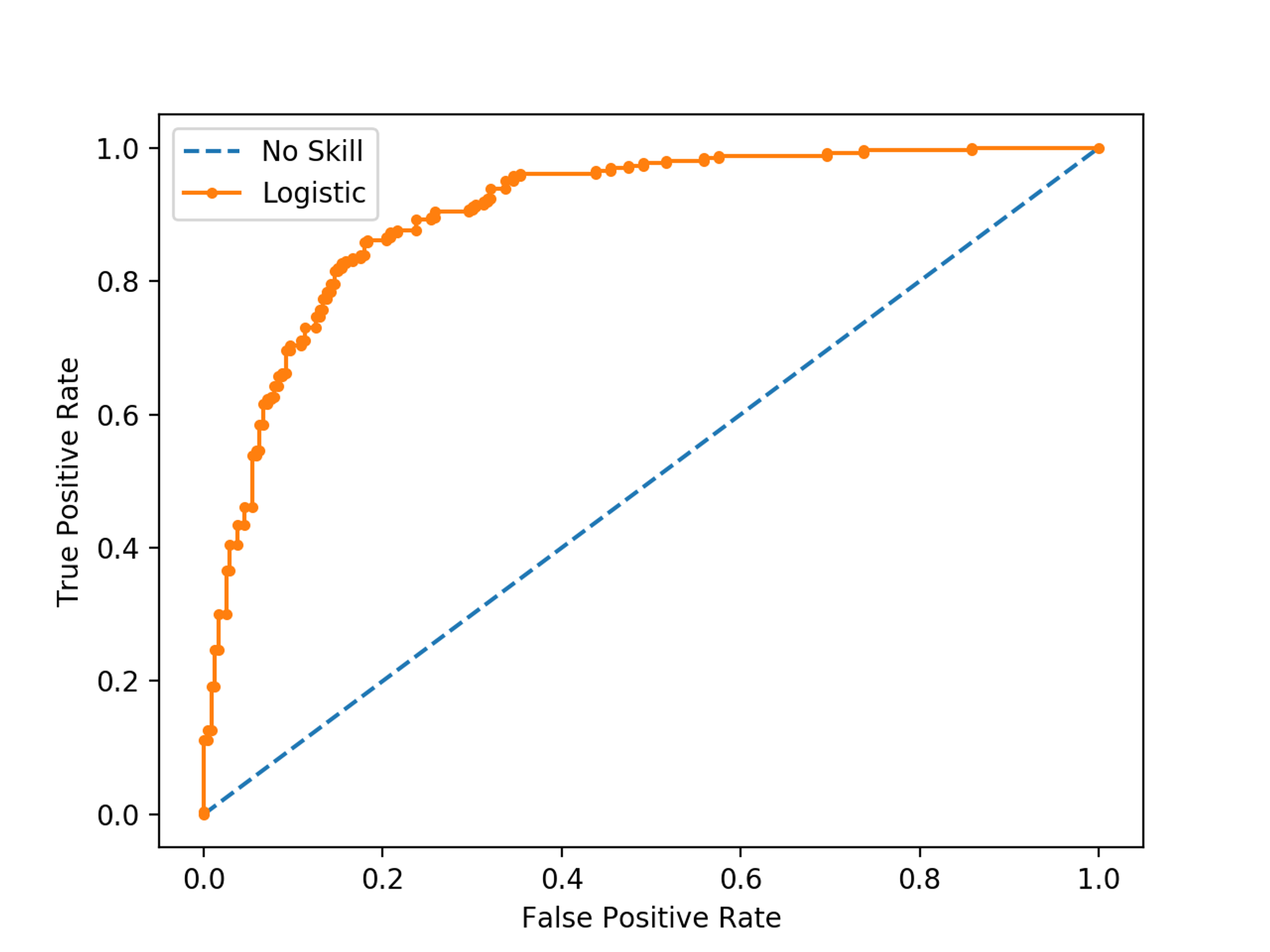
ROC Curve의 예는 위 그림과 같다. 가운데 직선은 ROC 곡선의 최저값으로, 랜덤 수준의 이진 분류에서의 ROC Curve이다. ROC Curve가 가운데 직선에 가까울수록 성능이 떨어지는 것이며, 멀어질수록 성능이 뛰어난 것이다.
FPR(X축)과 Threshold와의 관계
ROC Curve는 FPR을 0부터 1까지 변화시키면서 TPR의 변화 값을 구한다. 그럼 어떻게 FPR을 0부터 1까지 변경시킬 수 있을까? 결론부터 말하면 Threshold를 1부터 0까지 변화시키면 된다.
FPR의 정의를 다시 보면, 이다.
•
FPR이 0이려면, FP를 0으로 만들면 된다. 아예 Positive로 예측한 게 없어야 하므로, Threshold가 1이면 된다.
•
FPR이 1이려면, TN을 0으로 만들면 된다. 아예 Negative로 예측한 게 없어야 하므로, Threshold가 0이면 된다.
ROC-AUC Score
결국 분류의 성능 지표로 사용되는 것은 ROC 곡선 면적에 기반한 AUC(Area Under Curve) 값이다.
AUC(Area Under Curve) 값은 ROC 곡선 밑의 면적을 구한 것으로, 1에 가까울수록 좋은 수치이다.
AUC 값이 커지려면, FPR이 작은 상태에서 알마나 큰 TPR을 얻을 수 있느냐가 관건이다. 가운데 직선에서 멀어지고, 왼쪽 상단 모서리 쪽으로 가파르게 곡선이 이동할수록 직사각형에 가까운 곡선이 되어 면적이 1에 가까워진다.
가운데 직선은 아까 말했듯 가장 기본적인 랜덤 수준의 이진 분류 ROC Curve로, ROC-AUC 값은 0.5이다. 따라서 보통의 분류 모델은 0.5 이상의 ROC-AUC 값을 가진다.