
SPPNet 논문 요약
Table of Contents
Summary
•
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
•
Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
•
ECCV 2014
•
2014 ILSVRC Classification에서 3등.
Remind: R-CNN의 단점 중에서...
•
CNN의 입력을 위해 RoI에 warping 또는 crop이 필요하다. (이미지 크기를 정사각형으로 맞춰줘야 한다.) 이 과정에서 이미지 정보 손실이 일어난다.
•
그리고, 모든 2k개의 RoI마다 CNN을 적용해야 하므로 느리다.
어떻게 개선하지?
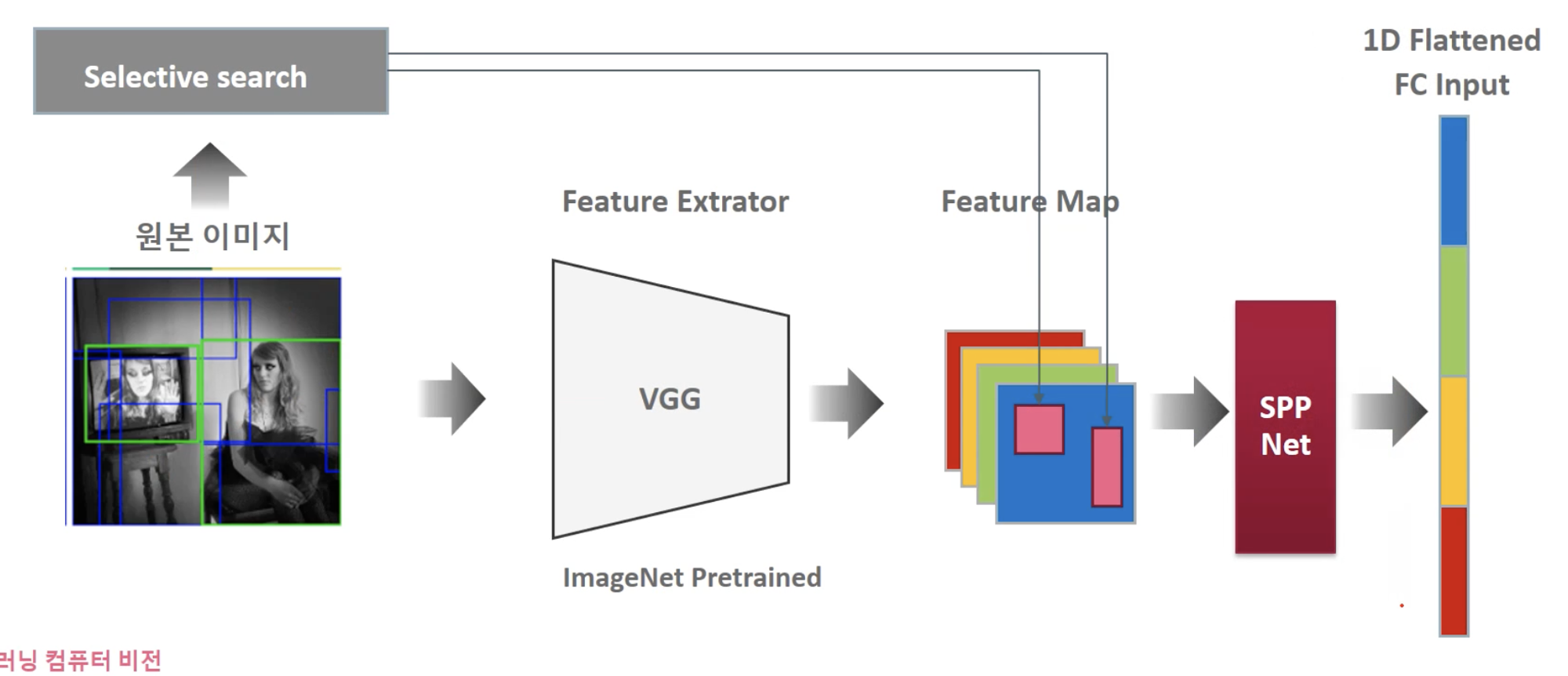
•
SPPNet은, 2k개의 RoI 이미지를 각각 CNN으로 Feature Extraction해서 예측하는 것이 아니고, 우선 원본 이미지에서 CNN으로 Feature Map을 생성한 뒤에, 원본 이미지에서 Selective search로 추천된 영역만 Feature map으로 매핑해서 해당 Feature map 영역을 사용한다.
•
즉, Selective search로 추천된 영역에 해당하는 Feature map 영역을 사용하는 것이다.
•
단, CNN으로 생성된 Feature Map에서 추출한 각 영역들은 크기가 제각각일 텐데, 알다시피 FC의 input은 고정 크기여야 한다.
◦
이 문제를 해결해주는 것이 후술할 Spatial Pyramid Pooling layer이다.

위: R-CNN, 아래: SPPNet
왜 입력 크기를 맞춰줘야 하는가?
•
CNN은 두 부분으로 나누어볼 수 있다:
◦
Conv. Layer와 Pooling Layer로 이루어진 앞부분
◦
FC와 Classifier가 있는 뒷부분
•
CNN에서 이미지의 크기를 정사각형으로 맞춰줘야 하는 이유는 뒷부분의 FC 때문이다.
◦
FC에 들어가는 input vector의 크기는 당연히 고정이여야 하므로.

사실 앞부분의 Convolution Layer가 있는 부분에는 고정 크기의 입력이 필요하지 않다. Convolution 필터는 알다시피 sliding window 방식으로 움직이기 때문에 이미지 크기나 비율에 상관없다. 단지 입력 크기가 고정되지 않으면 output으로 나오는 Feature map의 크기도 들쭉날쭉하기 때문에 FC의 input으로 들어갈 수 없는 것 때문이다.
SPM: Spatial Pyramid Matching
SPP를 이해하기 위해 우선 SPM을 이해할 필요가 있다. SPM을 이해하면 SPP는 따라오는 것이다.
Bag of Words
Bag of Words(BoW)는 자연어 처리 분야에서 문서를 분류하기 위한 방법 중 하나로, 단순히 단어의 빈도만을 고려해서 이 문서가 어떤 종류의 문서인지 판단하는 방법이다. 문장을 단어별로 다 쪼개서 가방에 넣는 상황을 떠올려보자.
예를 들어, 어떤 문서에서 '패스', '골', '선수' 등의 단어가 많이 출현했다면 그 문서는 스포츠에 관련된 문서로 분류하고, '노출', '피사체', '구도' 등의 단어가 많이 출현했다면 사진에 관련된 문서로 분류해내는 식이다.
문맥은 고려되지 않는다. 단어의 순서들이나 앞-뒤 연관관계를 고려하지 않고 그냥 단어의 빈도만을 이용하기 때문이다.
Image Processing에서의 BoW
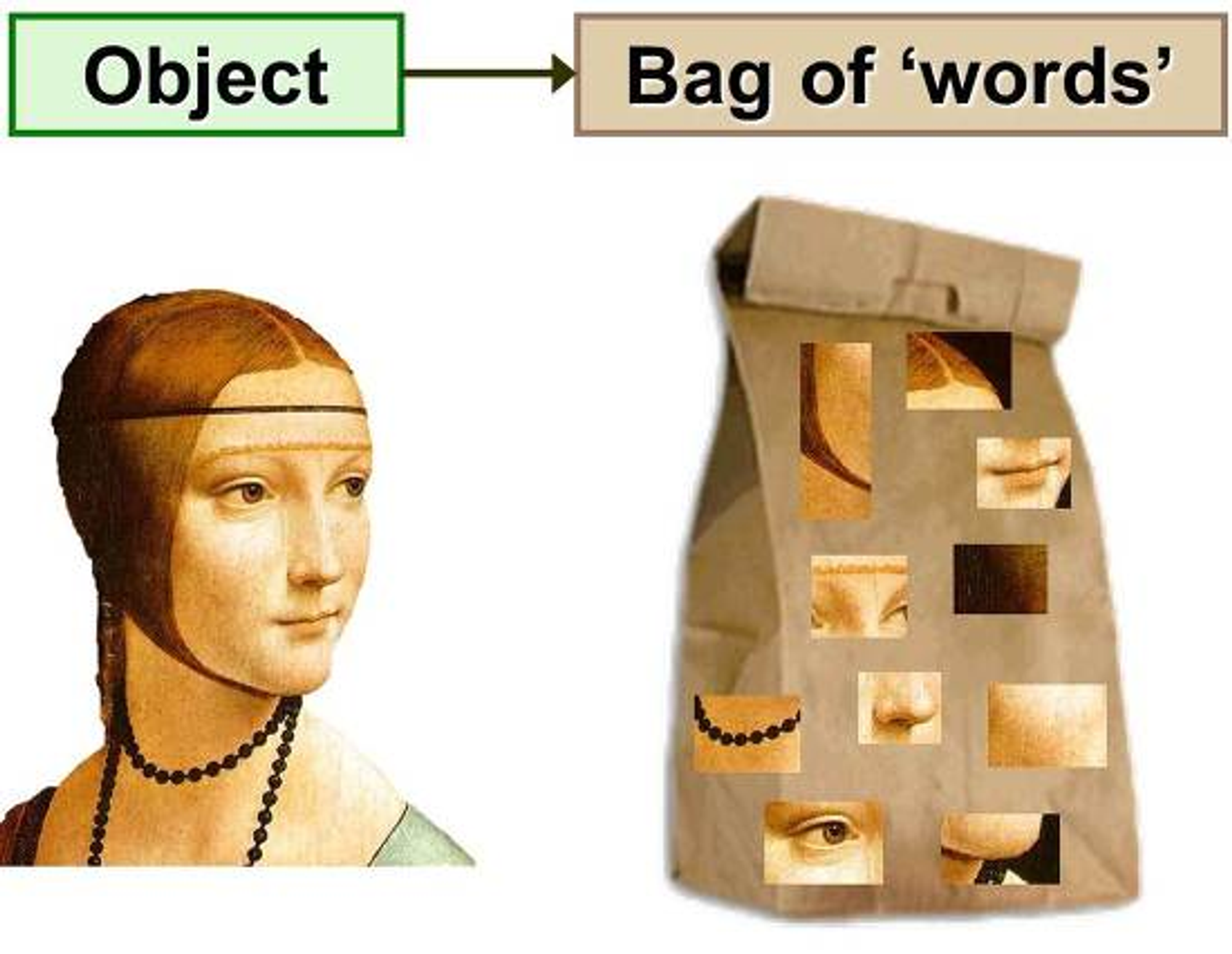
이미지 프로세싱 분야에서도 BoW 개념을 적용할 수 있다. 비슷하게 이미지를 여러 조각으로 쪼개서 가방에 넣는다고 생각하자. 이 쪼개진 이미지 조각들을 Local Feature로 생각할 수 있다.
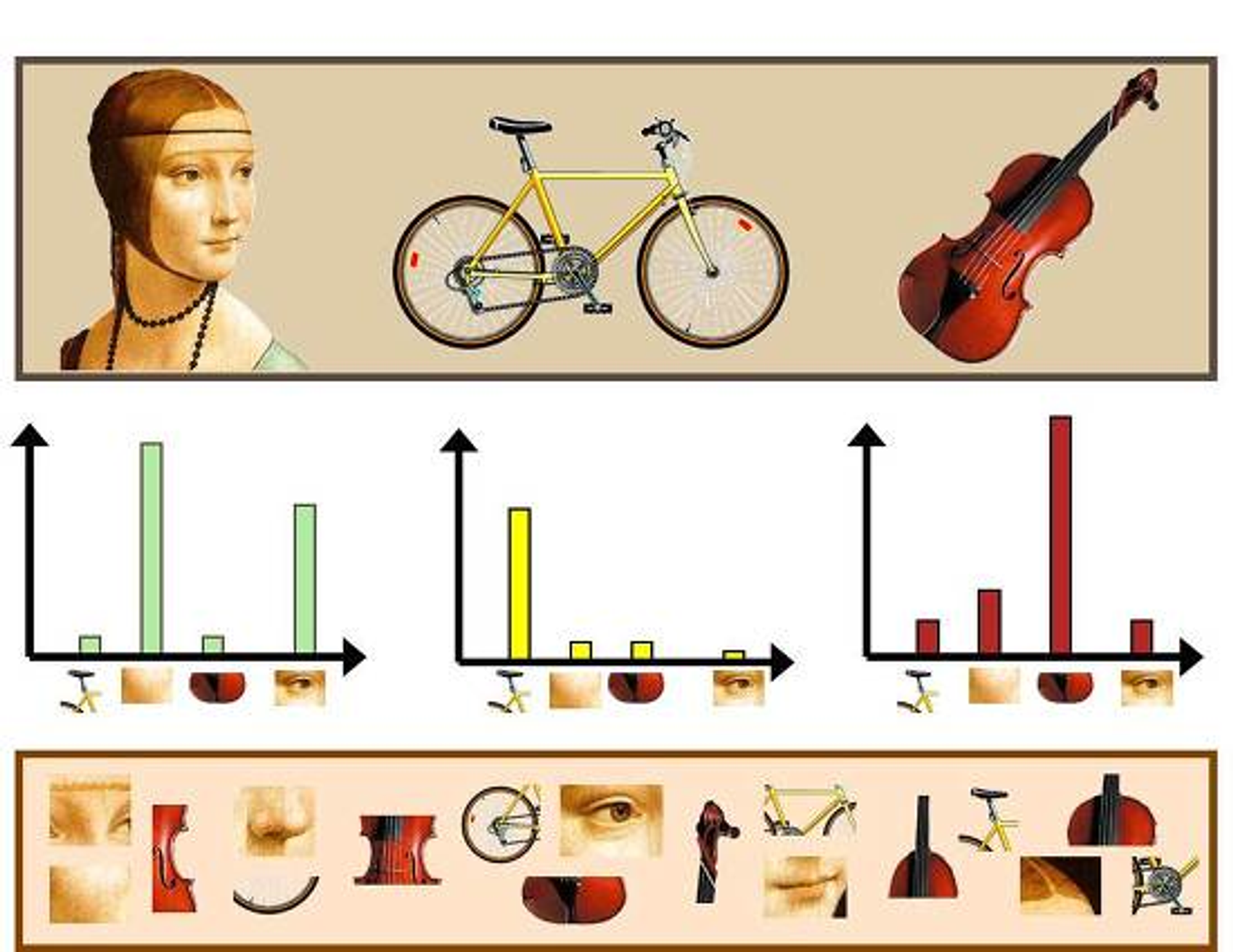
그러고 나면 Classification 과정은 위와 비슷하다.
어떤 이미지에서 사람의 Local Feature가 많이 나타난다면 이는 사람 이미지로 분류할 수 있고, 자전거의 Local Feature가 많이 나타난다면 자전거 이미지, 이런 식이다.
여기서도 똑같은 문제가 발생하는데, 문맥(위치 정보)가 고려되지 않는다는 것이다. 하나의 이미지에서 여러 Feature가 나타날 수 있는데, 이렇게 되면 정확한 Classification이 이루어지지 않는다. 가령 자전거를 탄 사람과 첼로가 같이 찍힌 이미지에서의 히스토그램을 상상해 보자.
Spatial Pyramid Matching
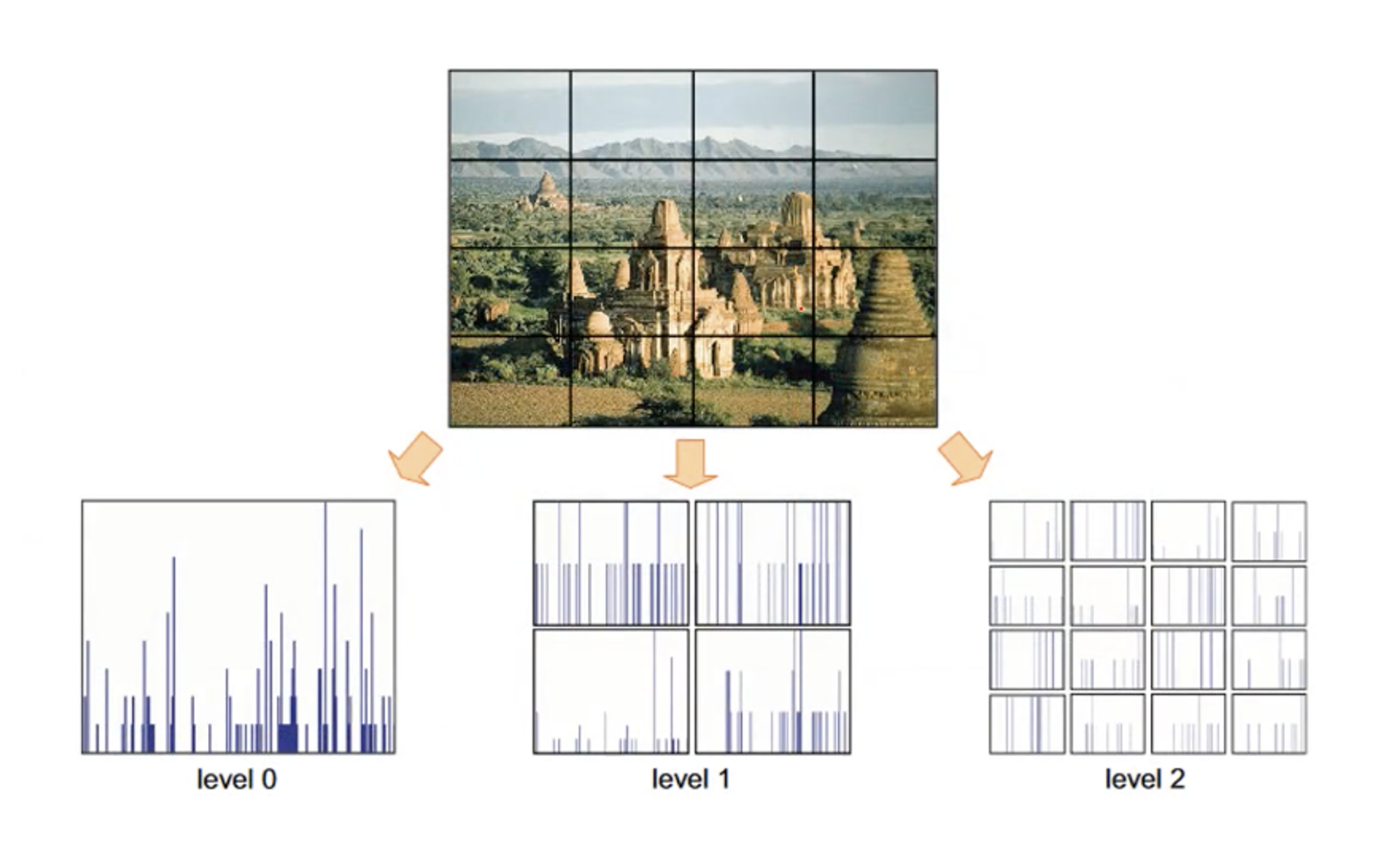
SPM은 이 문제를 '사분면을 쪼개는 것'으로 해결했다. 각 분면상에 나타나는 Feature의 빈도를 벡터화시키는 것이다.
위 그림에서 level 0은 전체 이미지에서의 Feature 빈도 히스토그램이고, level 1은 전체 이미지를 4등분해서 각 사분면에서의 Feature 빈도를 나타낸 것이고, level 2는 앞 과정을 사분면마다 한번씩 더 수행한 것이다.
결과적으로는 이 Feature들의 레벨별 빈도를 벡터화시키는 것이 목적이다. 예시를 하나 더 들어보자.
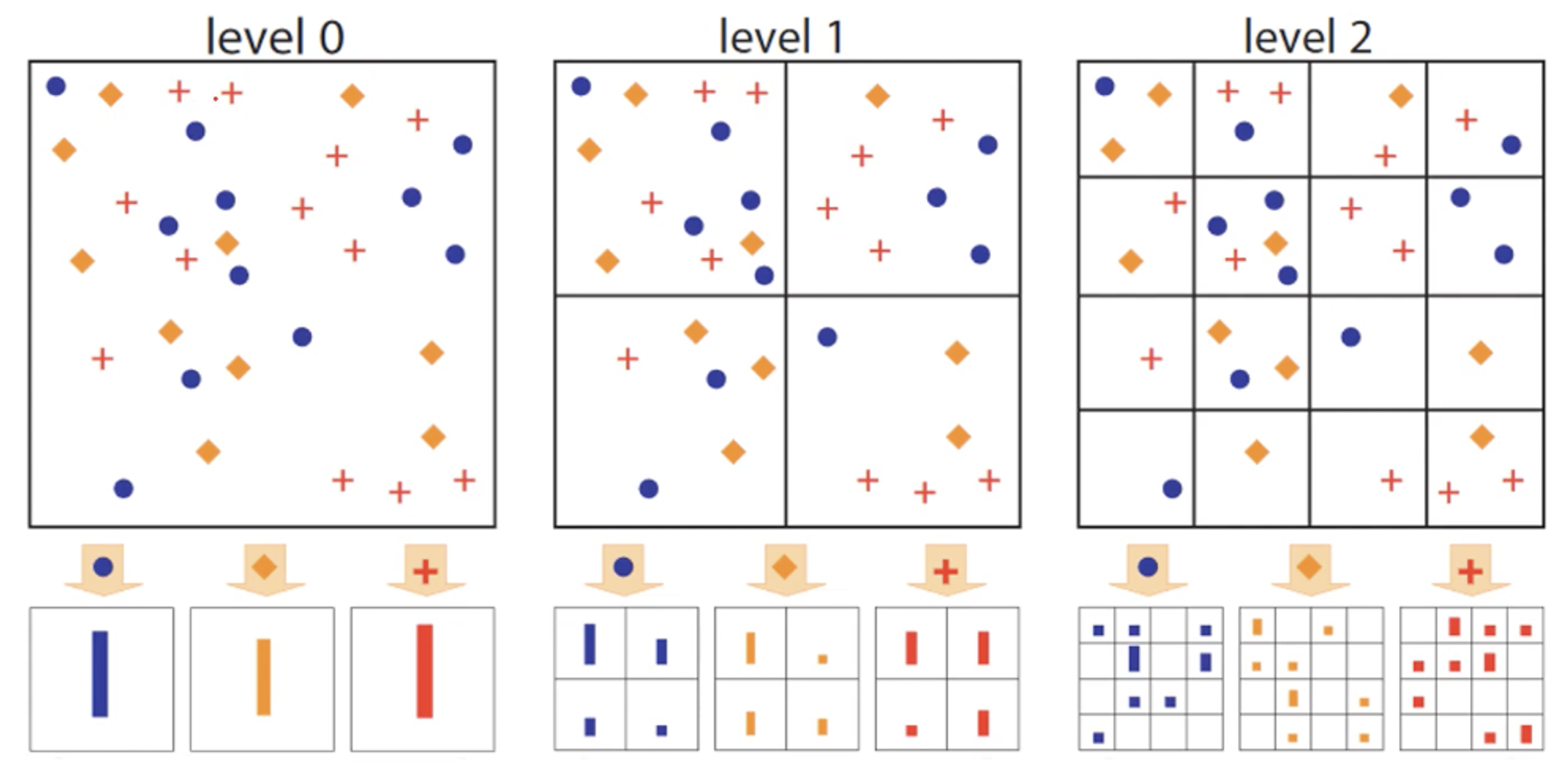
위 그림에서, level 0 기준으로 레이블별 빈도는 [11], [10], [12]이다.
level 1에서는 각 사분면별로 [5, 3, 2, 1], [4, 1, 3, 2], [4, 4, 1, 3]이다.
level 2에서는 [1, 1, 0, 1, 0, 3, 0, 2, 0, 1, 1, 0, 1, 0, 0, 0], [...], [..., 0, 0, 1, 2]와 같은 식으로 나타날 것이다.
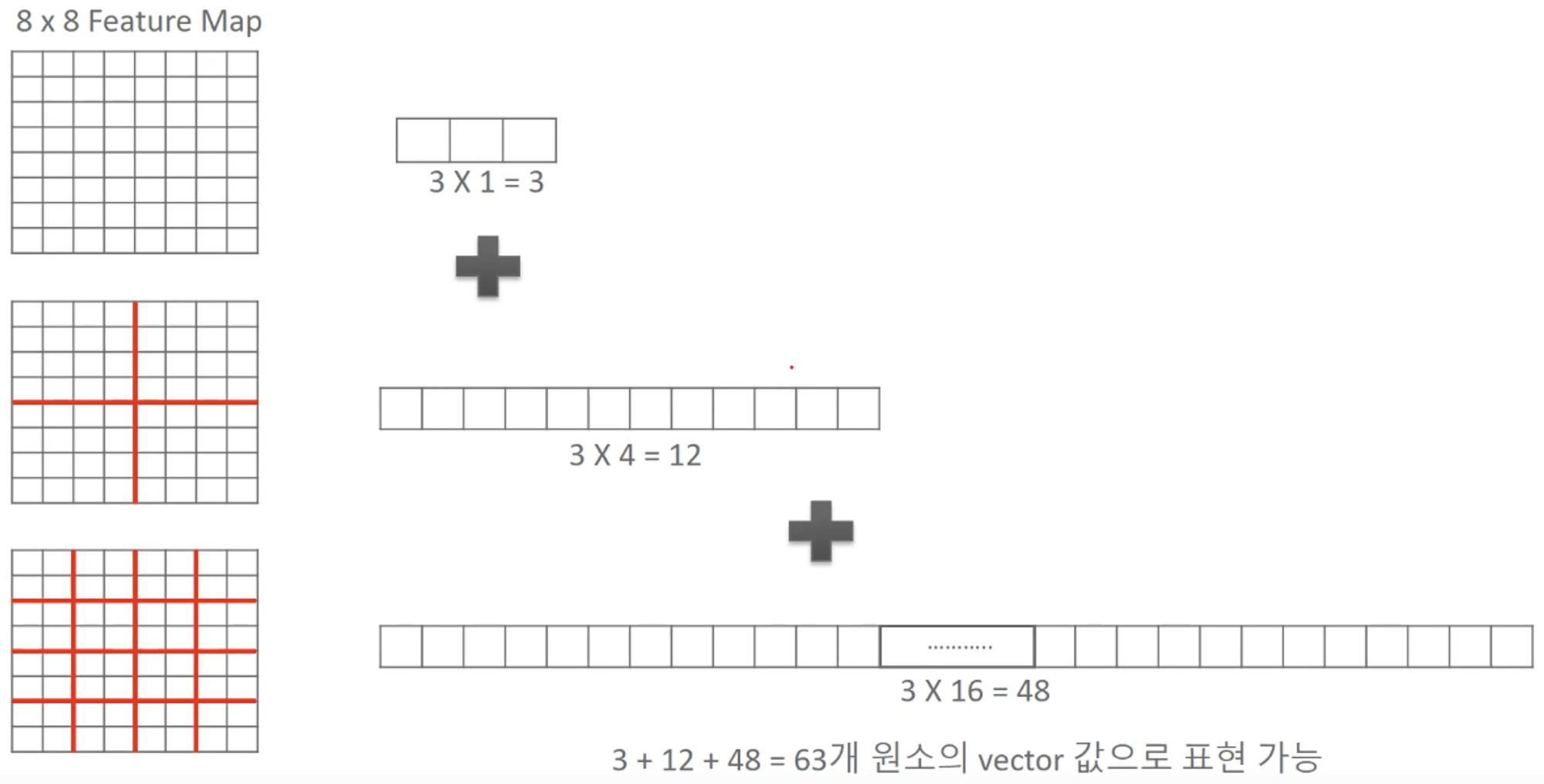
그리고 나서, 이 빈도들을 모두 붙여서 하나의 벡터로 만든다.
level 0에서는 전체 이미지에서 고려했고, Feature는 3개이므로 3개의 원소가 나온다.
level 1에서는 4개 영역에서 고려했고, Feature는 3개이므로 12개 원소가 나온다.
level 2에서는 16개 영역에서 고려했고, Feature는 3개이므로 48개 원소가 나온다.
따라서 level 0~2를 고려했을 때, 벡터 길이는 63이 된다.
레벨을 몇까지 고려할 것인지 (즉, 몇 단계까지 쪼갤 것인지)는 상황에 따라 다르다. 마음대로 하면 된다.
그리고 재미있는 사실은, 위 예시처럼 Feature Map이 정방형이 아니더라도 벡터의 크기는 일정하다는 것이다.
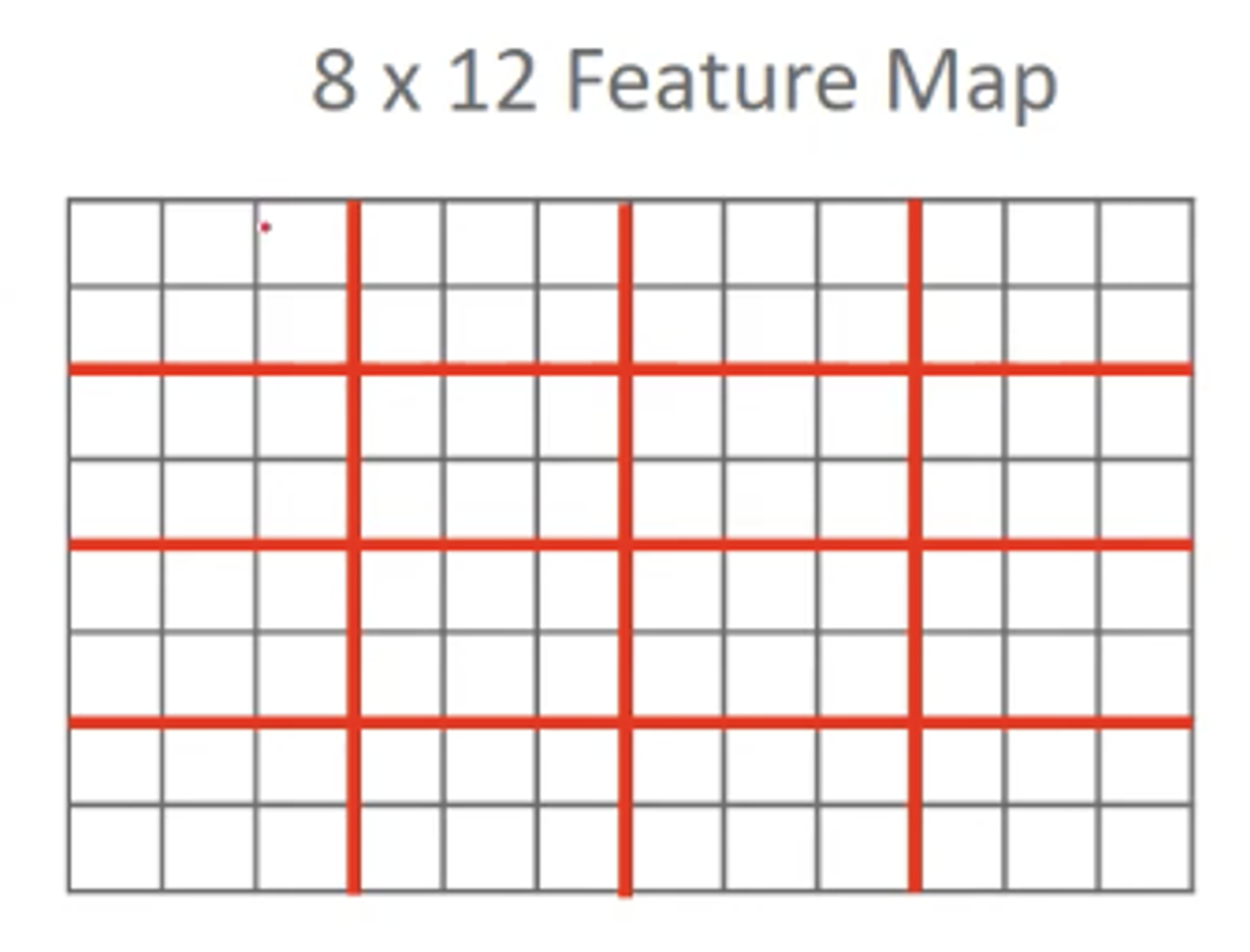
위와 같이 정방형이 아닌 8*12 크기의 Feature Map에서도 벡터의 길이는 63이다. 과정을 보면 알 수 있지만, 벡터 길이는 (이미지 크기에 종속되지 않고) 영역을 몇 개로 나누었는지, Feature가 몇 개인지에 따라 달라지기 때문이다.
다양한 Feature Map 크기에 대응할 수 있는 이유가 여기에 있다.
SPP: Spatial Pyramid Pooling
SPP는 위 SPM에서 각 영역별로 Feature 레이블의 각 빈도를 모두 저장하는 것이 아니고, 영역별 빈도들의 최댓값만 뽑아낸다. 영역별 빈도에 Max Pooling을 적용한 값을 이용한다고 생각하면 된다.
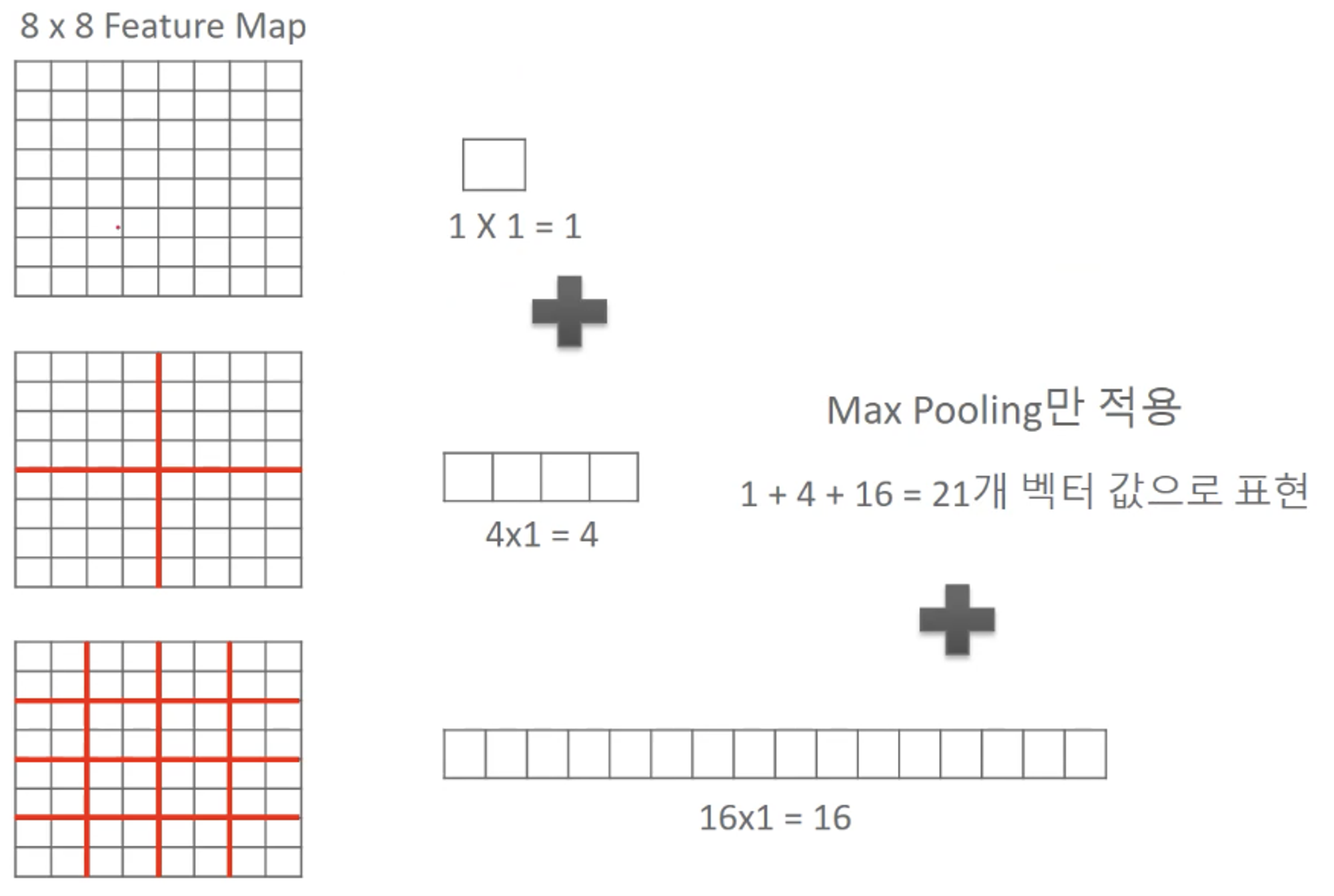
위의 8*8 Feature Map 예제를 다시 가져오면, SPP는 영역별로 Max Pooling이 적용되어서 나온 하나의 값만 벡터에 사용하므로 영역별로 1개의 값이 나오는 것을 볼 수 있다.
Network Structure
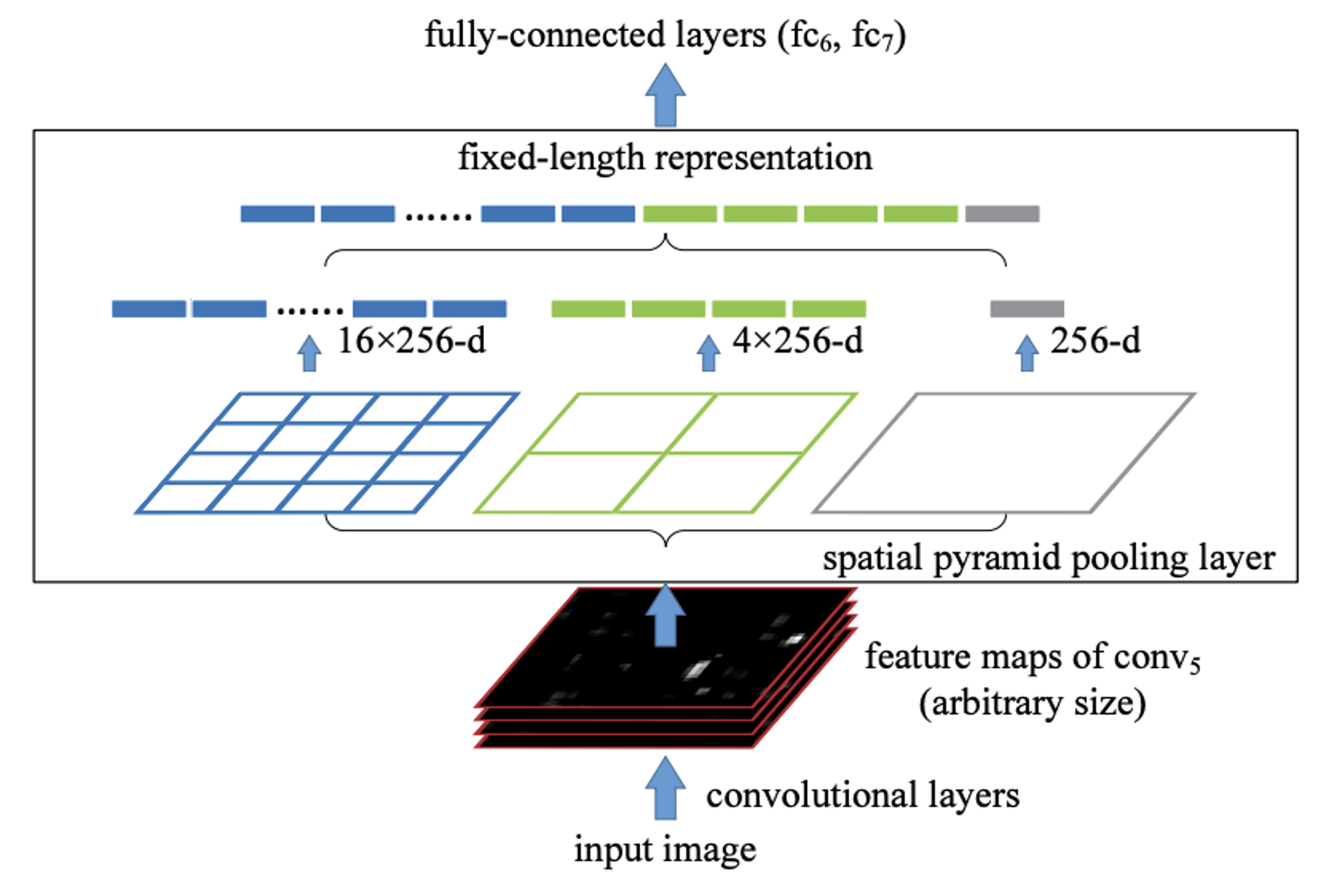
SPP를 설명했고, 이제 전체 네트워크 구조 내에서 SPP가 어떻게 사용되는지 알아보자.
우선 input image에서 CNN을 1회 돌려서 나온 Feature map을 Spatial Pyramid Pooling layer에 넣는다. 이 때 이 Feature map의 크기는 고정되지 않았음에 주목하자.
그리고 나서, SPP에서 설명했던 방식 그대로 수행한다. 이 때 앞에서 설명했던 level 0, level 1, level 2에 해당하는 각각을 피라미드라고 부른다.
가령 SPP layer에 입력되는 Feature map의 채널 크기가 256이라면, level 0 피라미드를 거치면 일정한 길이의 벡터가 1개 나오고, level 1 피라미드를 거치면 4개, level 2 피라미드를 거치면 16개 나온다. 이를 위처럼 이어붙이면 고정된 길이의 벡터가 완성되며, 이를 FC layer의 입력으로 넣어주는 것이다.
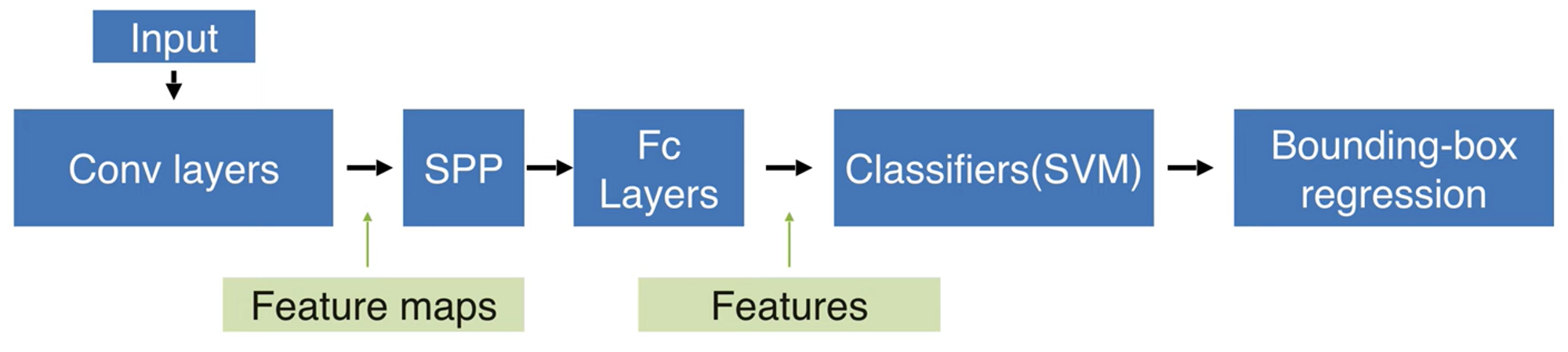
그리고 나서, FC의 output으로 나온 결괏값을 이용해 따로 SVM을 돌려 Classification을 수행하고, Bbox regression도 따로 수행한다.
전체 과정을 요약하면 다음 그림과 같다.
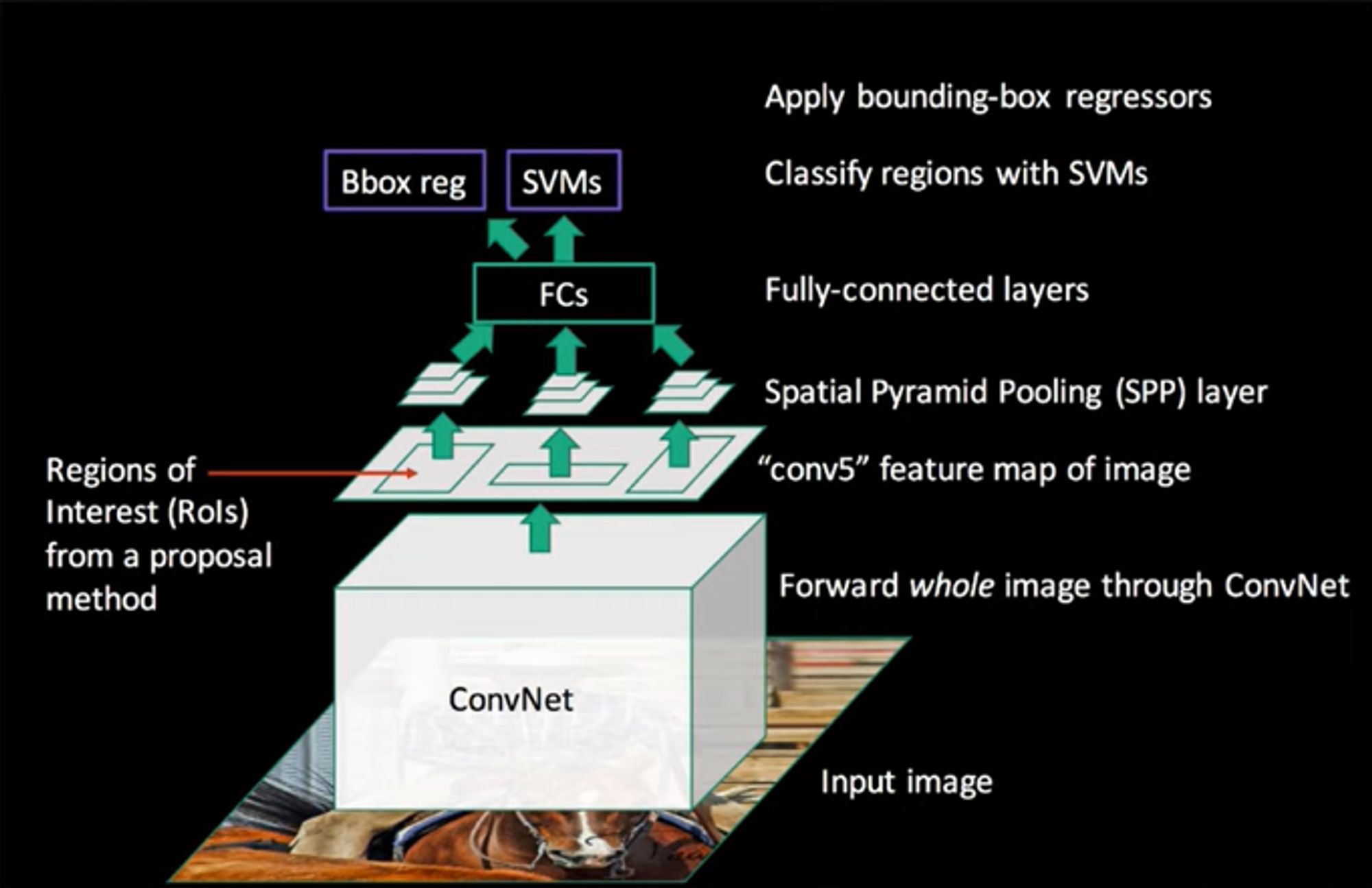
Conclusion
•
우선 R-CNN의 고질적인 문제를 해결했다. ConvNet 자체를 2000번 수행하는 것이 아니고, 1번만 수행되니까 연산은 엄청 줄었다.
•
하지만, 앞부분의 두 과정 순서만 바뀐 것 빼고는 R-CNN과 같은 구조이다.
◦
똑같이 Multi-stage pipeline이고, 대용량 저장 공간이 필요하다.
◦
순서를 바꾸고 Spatial Pyramid Pooling 방법을 도입함으로써 연산량은 많이 줄였지만, 그래도 Bbox reg랑 SVM Classification이 따로 돌아가므로 SVM 학습이 따로 필요하고, 여러가지 복잡한 과정이 필요하다.
•
Fine tuning 시, 뒤에 이어지는 FC layer만 학습이 가능하고, 맨 처음에 원본 이미지가 통과하는 ConvNet을 학습시킬 수 없다고 한다. 정확도가 조금 떨어질 것이다.
•
(R-CNN과 비교하여) 정확도는 큰 차이가 없었다. 속도는 크게 줄었다고 한다.
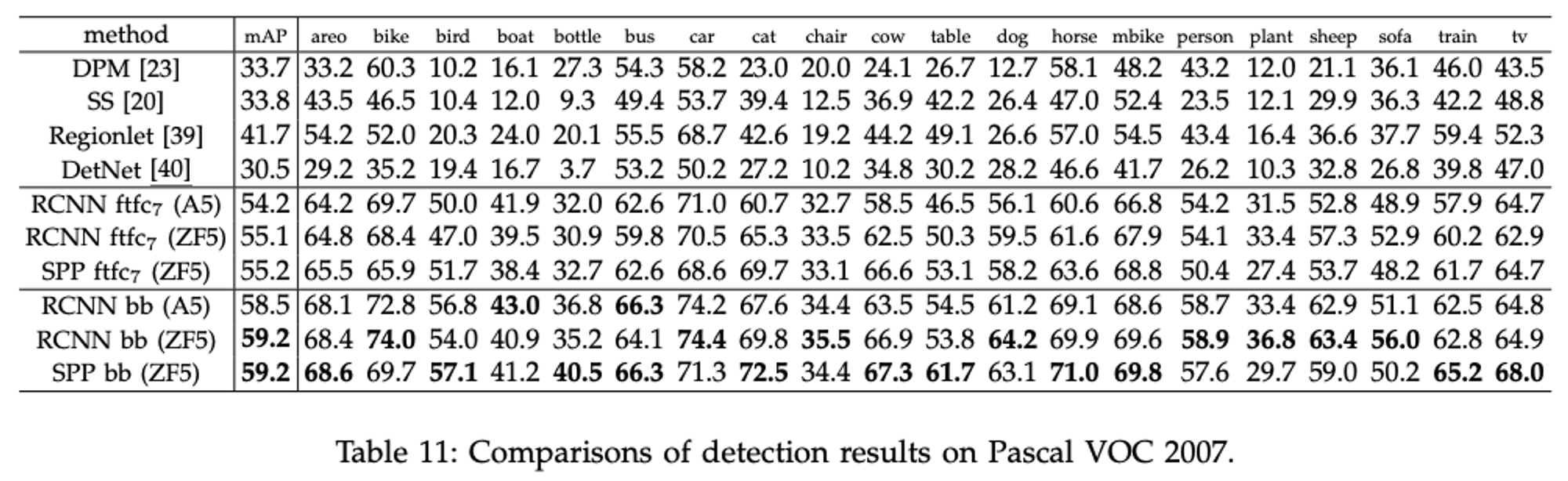
맨 밑의 RCNN과 SPP 두 개의 mAP를 보자. "bb"는 bounding box regression을 뜻한다.