
주식회사 이제이엔(EJN)에서 BI(Data) Team 인턴으로 9주간 근무하면서 진행한 내용들을 정리해 보았습니다.
Table of Contents
프로젝트의 정의와 목적
저는 이제이엔 BI(Data) Team에서 9주간 "머신러닝을 이용하여 추천 서비스에 부적합한 트위치 스트리머 판별" 프로젝트를 수행했습니다.
트위치에는 다양한 한국 스트리머(채널)들이 존재합니다. 하지만, 이들 중에는 순수한 게임/일상 스트리밍이 아닌 불법적인 정보를 제공하거나, 평균 방송 시간이 비정상적으로 긴 경우(24시간 중 23시간 방송) 등 추천 서비스의 목적에 부합하지 않는 스트리머들도 있습니다.

리니지 불법 도박 방송 (1)
리니지 불법 도박 방송 (2)
TV 방송 다시보기 (1)
TV 방송 다시보기 (2)
EJN에서는 "이 채널을 시청한 사람들이 많이 시청한 채널"을 비롯하여 파트너 스트리머를 위한 다양한 추천 서비스를 준비 중에 있습니다. 하지만, 불법 도박 방송이나 TV 방송 다시보기를 중계하는 스트리머가 추천 리스트에 등재되는 것은 서비스의 목적상 적절하지 않습니다. 따라서 이러한 "추천 시스템에 부적합한 스트리머"들을 걸러내는 작업이 우선되어야 합니다.
이러한 "부적합 스트리머"들을 가장 쉽게 판별하는 방법은 당연히 모든 스트리머들을 일일히 보면서 직접 판별하는 것입니다. 하지만 예상할 수 있듯 이러한 전수조사 방법으로는 시간이 너무 오래 걸리며, 특히나 여러 스트리머들 중 부적합 스트리머가 존재하는 비율을 생각해볼 때 이는 비효율적인 방법입니다. 따라서 스트리머들의 평균 방송 시간, 평균 시청자 수, 받은 채팅 수 등 기본적인 수치를 가지고 통계적 방법 및 머신러닝을 통해 부적합 스트리머를 일차적으로 판별해내는 것을 목표로 하였습니다.
이 프로젝트는 아무것도 레이블링되지 않은 최초 데이터셋에서부터 시작하여 문제 제기, EDA, 초기 레이블 구축부터 머신러닝 모델을 통해 최종 추론 결과까지 얻는 일련의 과정이 포함되어 있습니다. EJN에서 처음 수행해보는 머신러닝 프로젝트라 부족한 부분도 많았지만, 아무것도 없는 데이터에서 어떻게 초기 레이블을 구축하고 레이블링된 데이터를 늘려나갔는지, 모델 평가는 어떻게 진행하였는지 등 눈여겨볼 만한 부분은 많다고 생각합니다.
수집한 Raw 데이터
2020-09-01 ~ 2020-12-31 기간 동안의 데이터를 분석 및 모델 추론에 사용하였으며, 모든 데이터는 Twitch API를 통해 수집한 공개된 데이터입니다. 또한, 분석에 사용하지 않는 사용자 관련 고유 정보(프로필 사진 등)는 해시화하여 별도로 관리하였습니다.
Stream, Segment
트위치에서는 스트리머가 하나의 Stream을 진행하면서, 중간에 Stream 제목을 바꾸거나 게임 카테고리를 변경할 수 있습니다. 이러한 상황에서 단순히 Stream을 하나의 정보로만 볼 수는 없어서, 하나의 Stream 내에서 동일한 제목과 게임 카테고리로 진행되는 구간을 Segment로 나누어 관리하였습니다. 즉, 하나의 Stream이 여러 Segment로 이루어지는 관계입니다. 구조를 간단하게 나타내면 다음과 같습니다.
Stream 1 = ----[ Segment 1 ]---------[ Segment 2 ]--[ Segment 3 ]------------
Plain Text
복사
Viewers, Chatters
데이터 분석을 위해 시청자(뷰어) 정보와 채팅에 참여한 사람(채터) 정보도 수집하였습니다. Viewers 테이블과 Chatters 테이블의 Row 한 개는 한 Segment당 시청자 한 명과 채팅에 참여한 사람 한 명을 나타냅니다. 이 두 테이블을 Segment, Channel 테이블과 잘 결합하여 유의미한 피쳐를 뽑아내야겠다고 생각하였습니다.
Channel
마지막으로, 가장 중요한 (판별의 대상이 되는) 채널 데이터를 수집하였습니다. 채널 데이터 자체에는 해시화된 채널 id와 채널 생성일, 갱신일 등이 있을 뿐으로, 단순히 채널 테이블만을 이용하여 부적합 스트리머를 가려내는 것은 거의 불가능하다고 생각하였습니다.
이러한 5개 테이블이 주어진 상태에서 분석을 진행해야 했습니다. 우선 기존 피쳐들을 응용하여 새로운 피쳐들을 만들어낸 후, 피쳐들의 사분위수, 각 피쳐들 간의 상관관계 등 통계적 수치/방법을 이용해 EDA를 수행하고자 하였습니다.
데이터 전처리와 Input features 추가

데이터 전처리 작업은 PySpark 환경에서 수행하였습니다.
진행하기에 앞서, 데이터들이 모두 string 타입으로 저장되어 있었기 때문에 칼럼에 따라 적절히 타입 캐스팅을 진행하였습니다.
우선 기존 피쳐들을 응용해 실제 Input feature로 사용할 수 있을만한 피쳐들을 만들어 보았습니다.
Segment, Stream 테이블
duration — Segment/Stream 길이
Segment와 Stream 테이블의 각 row에는 최종 갱신 일시를 뜻하는 updatedAt 칼럼과 생성 일시를 뜻하는 createdAt 칼럼이 있습니다. 최종 갱신일이 Segment 종료 일시와 동일함을 확인한 뒤, updatedAt에서 createdAt을 빼서 Segment 길이 칼럼을 만들었습니다. Stream 길이 칼럼도 동일한 방식으로 생성했습니다.
df_sa_segment = df_sa_segment.withColumn('duration', F.unix_timestamp('updatedAt') - F.unix_timestamp('createdAt'))
df_sa_stream = df_sa_stream.withColumn('duration', F.unix_timestamp('updatedAt') - F.unix_timestamp('createdAt'))
Python
복사
ccvAvg — 평균 동시 시청자 수
마찬가지로 Segment의 각 Row에는 총 동시 시청자 수를 뜻하는 ccvSum과 집계 횟수를 뜻하는 logCount 칼럼이 있습니다. ccvSum / logCount는 평균 동시 시청자 수가 되고, 이를 분석에 이용할 수 있을 것이라 생각하여 새로운 칼럼을 추가하였습니다.
참고: CCV란 동시 시청자 수를 뜻하는 용어입니다.
df_sa_segment = df_sa_segment.withColumn('ccvAvg', df_sa_segment['ccvSum'] / df_sa_segment['logCount'])
df_sa_stream = df_sa_stream.withColumn('ccvAvg', df_sa_stream['ccvSum'] / df_sa_stream['logCount'])
Python
복사
total_viewers — 시청자 수 합계
Viewers 테이블의 각 Row에는 해당 시청자가 어느 Segment/Stream에 속하는지 streamTwitchId 칼럼과 segmentTwitchId 칼럼이 있습니다. 이를 이용해 해당 Segment와 Stream을 시청한 시청자 수를 계산하여 새 칼럼으로 추가하였습니다.
total_viewers = df_sa_viewers.groupBy('segmentTwitchId').agg(F.count('segmentTwitchId').alias('total_viewers'))
df_sa_segment = df_sa_segment.join(total_viewers, df_sa_segment['id'] == total_viewers['segmentTwitchId'], 'left') \
.drop(total_viewers['segmentTwitchId'])
df_sa_segment = df_sa_segment.fillna(0, subset=['total_viewers'])
total_viewers = df_sa_viewers.groupBy('streamTwitchId').agg(F.count('streamTwitchId').alias('total_viewers'))
df_sa_stream = df_sa_stream.join(total_viewers, df_sa_stream['id'] == total_viewers['streamTwitchId'], 'left') \
.drop(total_viewers['streamTwitchId'])
df_sa_stream = df_sa_stream.fillna(0, subset=['total_viewers'])
Python
복사
total_chats — 달린 채팅 개수 합계
Chatters 테이블에도 Viewers 테이블과 마찬가지로 streamTwitchId 칼럼과 segmentTwitchId 칼럼이 존재하고, 이를 이용해 Segment와 Stream에 달린 채팅 개수의 합계를 새 칼럼으로 추가하였습니다. 특이 사항으로는 Chatters 테이블에는 한 시청자가 몇 개의 채팅을 달았는지가 chatCount 칼럼으로 존재하므로, 단순히 row 개수가 아닌 chatCount의 합으로 채팅 개수 합계를 계산했습니다.
total_chats = df_sa_chatters.groupBy('segmentTwitchId').agg(F.sum('chatCount').alias('total_chats'))
df_sa_segment = df_sa_segment.join(total_chats, df_sa_segment['id'] == total_chats['segmentTwitchId'], 'left') \
.drop(total_chats['segmentTwitchId'])
df_sa_segment = df_sa_segment.fillna(0, subset=['total_chats'])
total_chats = df_sa_chatters.groupBy('streamTwitchId').agg(F.sum('chatCount').alias('total_chats'))
df_sa_stream = df_sa_stream.join(total_chats, df_sa_stream['id'] == total_chats['streamTwitchId'], 'left') \
.drop(total_chats['streamTwitchId'])
df_sa_stream = df_sa_stream.fillna(0, subset=['total_chats'])
Python
복사
Channel 테이블
total_duration — 해당 채널의 방송 시간 합계
Stream 테이블에서 구한 duration을 이용해, 해당 채널에서 진행한 Stream의 duration을 모두 더하는 식으로 방송 시간 합계를 구했습니다.
total_duration = df_sa_stream.join(df_sa_channel, df_sa_stream['channelId'] == df_sa_channel['id'], 'left') \
.groupBy(df_sa_channel['id']) \
.agg(F.sum('duration').alias('total_duration'))
df_sa_channel = df_sa_channel.join(total_duration, df_sa_channel['id'] == total_duration['id'], 'left') \
.drop(total_duration['id'])
Python
복사
total_viewers, total_chats — 해당 채널의 총 시청자 수, 총 채팅 수
total_viewers, total_chats도 동일한 방식으로 계산하여 칼럼에 포함했습니다.
total_viewers = df_sa_stream.groupBy('channelId').agg(F.sum('total_viewers').alias('total_viewers'))
df_sa_channel = df_sa_channel.join(total_viewers, df_sa_channel['id'] == total_viewers['channelId'], 'left') \
.drop(total_viewers['channelId'])
Python
복사
total_chats = df_sa_stream.groupBy('channelId').agg(F.sum('total_chats').alias('total_chats'))
df_sa_channel = df_sa_channel.join(total_chats, df_sa_channel['id'] == total_chats['channelId'], 'left') \
.drop(total_viewers['channelId'])
Python
복사
game_null_duration — 게임이 null인 상태로 방송한 시간 합계
TV 중계 방송과 같은 케이스를 몇 번 목격하면서 직관적으로 느낀 것은, 이들이 모두 게임 카테고리를 공란으로 둔 채 방송한다는 것이었습니다. 따라서 게임이 null인 상태로 방송한 시간이 방송의 대부분이라면 중계 방송으로 볼 수 있을 것이고, 이것이 중요한 피쳐가 될 수 있을 것이라 생각했습니다.
game_null_duration = df_sa_segment.where(df_sa_segment['game'].isNull()).groupBy('channelId').agg(F.sum('duration').alias('game_null_duration'))
df_sa_channel = df_sa_channel.join(game_null_duration, df_sa_channel['id'] == game_null_duration['channelId'], 'left') \
.drop(game_null_duration['channelId'])
Python
복사
is_default_name — 채널명(name)과 아이디(description)가 같은가?
트위치에서는 계정을 생성하고 나면 채널명은 기본값으로 아이디로 설정되며, 향후에 스트리머들이 채널명을 따로 설정할 수 있습니다.
이 직관도 부적합 채널들을 몇 번 목격하면서 얻은 것으로, 부적합 채널의 경우 채널명을 따로 설정하지 않은 채 기본 채널명(아이디와 동일)으로 방송하는 경우가 많았습니다. 이 또한 중요한 인사이트라고 생각하여 따로 default name인지 여부를 나타내는 피쳐를 만들었습니다.
game_null_duration = df_sa_segment.where(df_sa_segment['game'].isNull()).groupBy('channelId').agg(F.sum('duration').alias('game_null_duration'))
df_sa_channel = df_sa_channel.join(game_null_duration, df_sa_channel['id'] == game_null_duration['channelId'], 'left') \
.drop(game_null_duration['channelId'])
Python
복사
레이블 정의 및 초기 레이블링
지금까지 분석을 위한 피쳐들을 마련했고, 이제 EDA를 통해 Outlier 탐지 및 제거, 피쳐 간의 상관관계 조사 등의 작업을 수행할 것입니다. 단, 지금까지 사용한 데이터들은 하나도 레이블되지 않았다는 것을 유념해야 합니다.
이 프로젝트는 이진 분류, 즉 Supervised Learning에 해당하기 때문에 데이터에는 반드시 레이블이 필요합니다. 이 프로젝트에서의 레이블은 "채널의 부적합 여부"가 될 것이고, 부적합한 경우는 1로, 그렇지 않은 경우는 0으로 레이블링하면 될 것입니다.
불균형한 레이블 클래스를 가지는 데이터에서는 많은 데이터 중 중점적으로 찾아야 하는 매우 적은 수의 레이블에 1, 그렇지 않은 경우에 0을 부여하는 경우가 많습니다. 가령 암 검출 Task에서는 암인 경우가 1, 암이 아닌 경우가 0이고, 금융사기 검출 같은 Task에서는 사기인 경우가 1, 정상인 경우가 0인 경우가 일반적입니다.
아무것도 없는 데이터셋에서 초기 레이블링은 (어쩔 수 없이) 수작업으로 진행했습니다. 무작위로 채널들을 조사하여 53378건의 채널 데이터 중 42건의 부적합 채널을 찾았고, 이들을 모두 1로, 나머지는 모두 0으로 하여 Channel 테이블에 레이블 칼럼 illegal을 새로 만들었습니다.
sa_channel = sa_channel.withColumn('illegal', F.when((sa_channel['channelId'].isin(illegal_list)) | (sa_channel['description'].isin(illegal_desc_list)), 1).otherwise(0))
Python
복사
이 데이터로 초기 모델을 훈련한 뒤 추론 결과에서 수작업으로 부적합 채널들을 추려내 레이블링하고, 레이블링된 데이터로 다시 모델을 훈련하여 나온 결과에서 부적합 채널들을 추려내고... 이러한 과정을 일정 수준까지 반복하여 레이블링된 데이터들을 늘려 나갈 예정이었습니다.
EDA (Exploratory Data Analysis)
Outlier 제거
위에서 레이블링한 Channel 테이블에 생성했던 피쳐들에 대해 통계치를 확인하고, 우선 기본적인 Outlier를 제거하는 작업을 수행했습니다.
+-------+------------------+
|summary| total_duration|
+-------+------------------+
| count| 63851|
| mean| 207204.4259761006|
| stddev|480215.33271022077|
| min| 0|
| max| 9519067|
+-------+------------------+
Plain Text
복사
+-------+------------------+
|summary| total_viewers|
+-------+------------------+
| count| 63851|
| mean|3712.9835084806814|
| stddev| 65475.50704477129|
| min| 0|
| max| 6169836|
+-------+------------------+
Plain Text
복사
+-------+------------------+
|summary| total_chats|
+-------+------------------+
| count| 63851|
| mean|16773.672142957825|
| stddev| 126662.2465416425|
| min| 0|
| max| 9334703|
+-------+------------------+
Plain Text
복사
+-------+------------------+
|summary|game_null_duration|
+-------+------------------+
| count| 7148|
| mean|13232.056099608282|
| stddev| 98957.62162616749|
| min| 0|
| max| 6968555|
+-------+------------------+
Plain Text
복사
Channel 테이블에 생성한 4개의 수치형 피쳐들의 통계치를 확인해 보았습니다. 모두 0 값이 존재하고, 0 값의 경우 잘못 측정된 것인지, 실제로 해당 수치가 0인지 알기 어렵습니다. 또한, total_duration이 0인 경우와 같이 방송 시간이 실제로 0이라면(방송이 전혀 진행되지 않았다면) 분석에 쓸모없는 데이터로 간주해도 무방합니다. 따라서 다음과 같이 데이터에서 사용하지 않아도 될 부분을 정의하고, 삭제하였습니다.
•
total_duration이 300(5분) 미만인 채널은 제거
•
total_chats가 0인 채널은 제거
•
total_viewers가 0인 채널은 제거
분포 확인 및 가설 세우기
total_duration
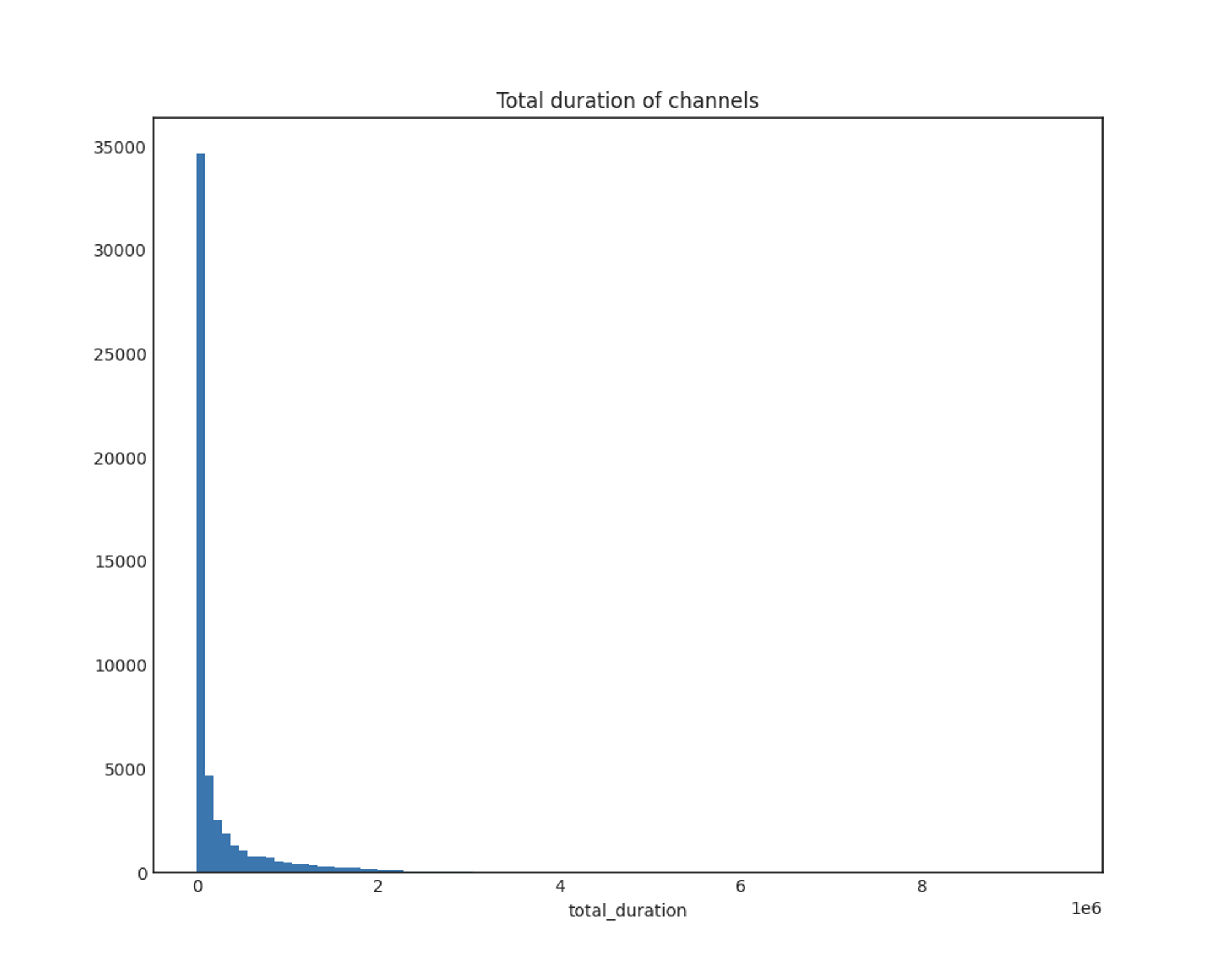
Total duration of channels
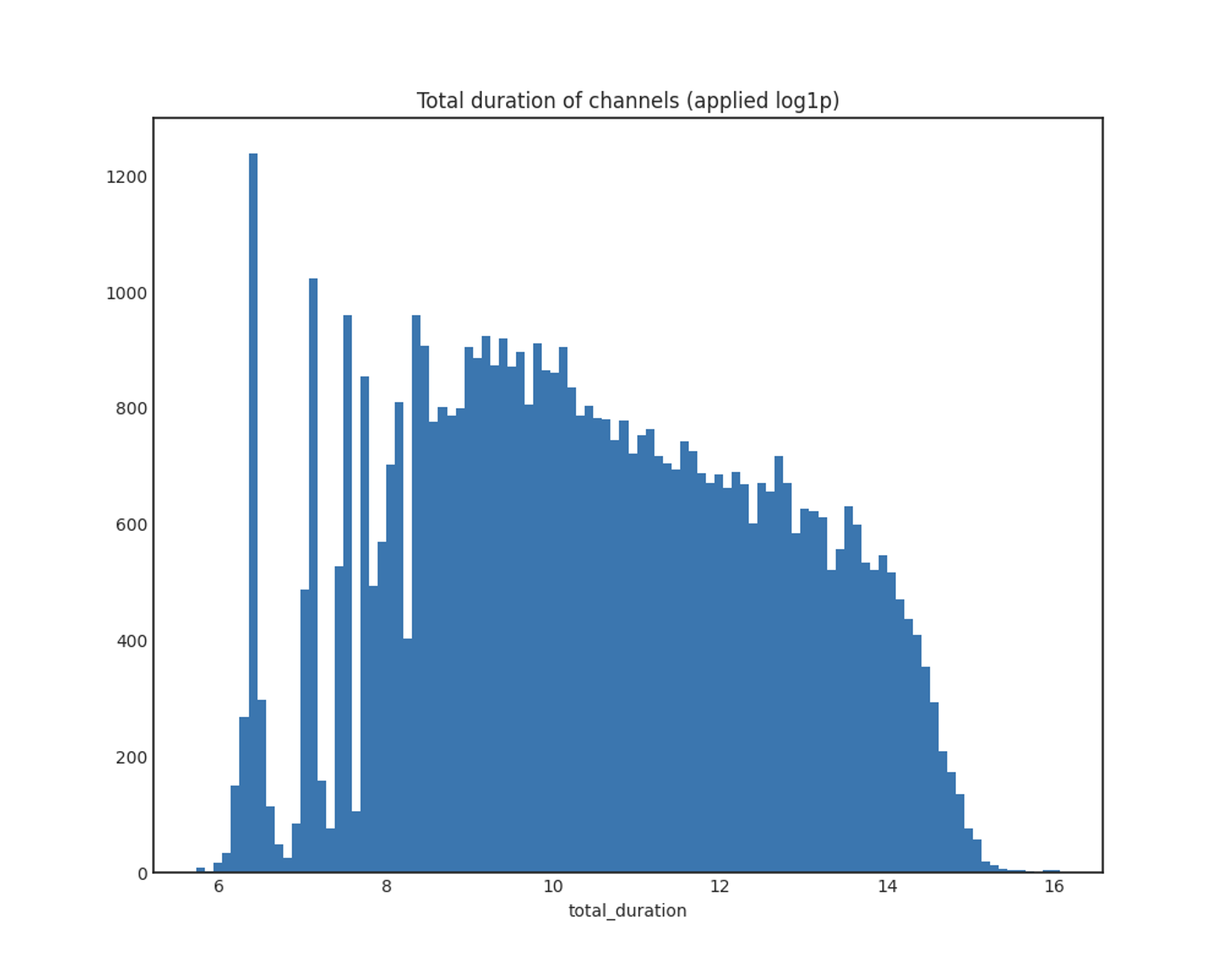
Total duration of channels (applied log1p)
x축: 방송 총 길이(초)
y축: 채널 개수
전형적인 왼쪽으로 skew된 분포를 보이며, log1p 함수를 적용한 분포는 대체로 정규분포를 따릅니다.
log1p를 적용한 데이터의 plot에서, 앞의 total_duration이 작은 부분이 대부분을 차지하는 데에 유의해야 할 것 같습니다. total_duration이 작다는 것은 채널 자체의 방송 시간이 얼마 안 된다는 의미이므로, 아마 지속적으로 홍보해야 하는 불법 방송보다는 테스트용으로 잠깐 켜 본 경우가 대다수일 것으로 예상했습니다.
total_viewers
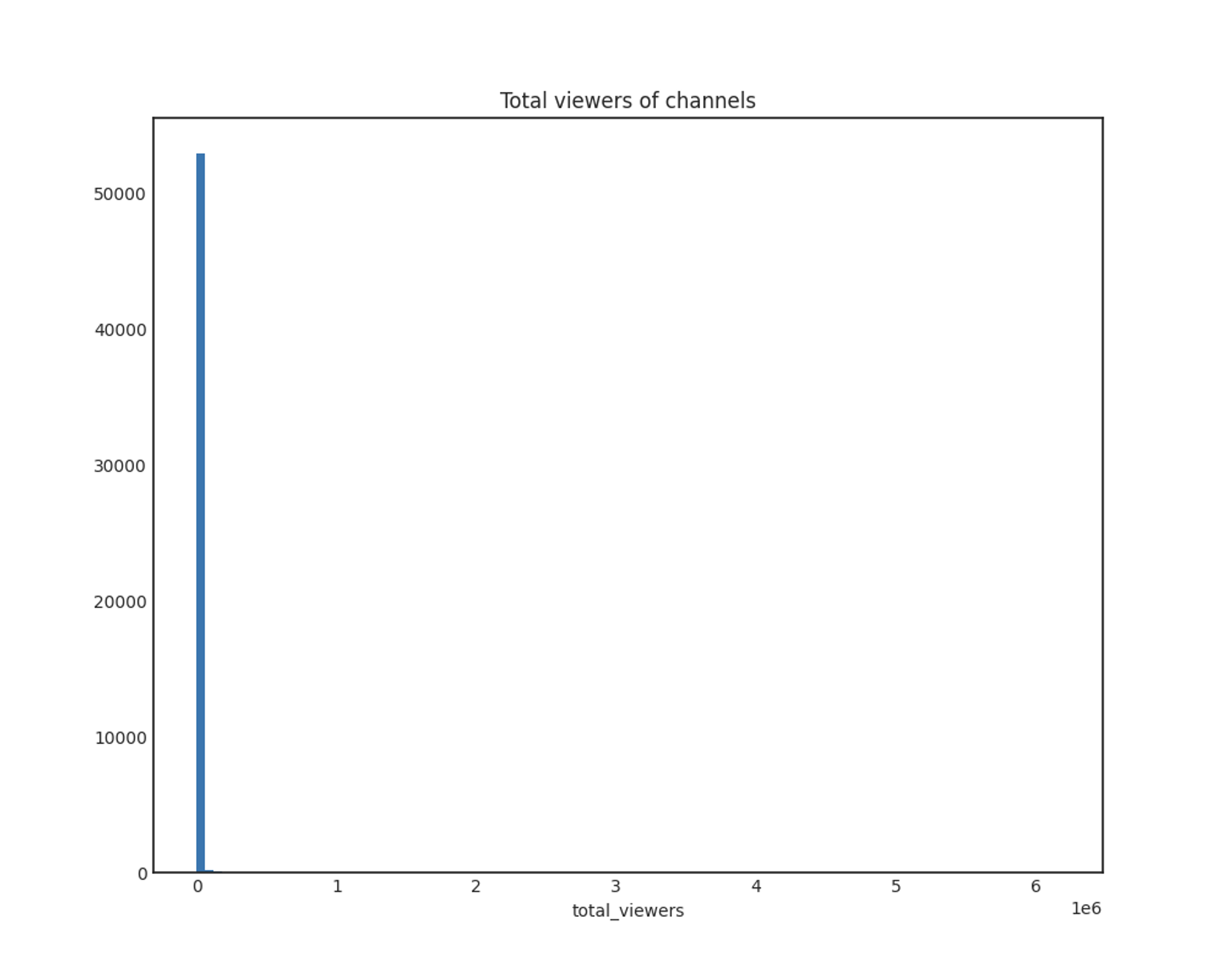
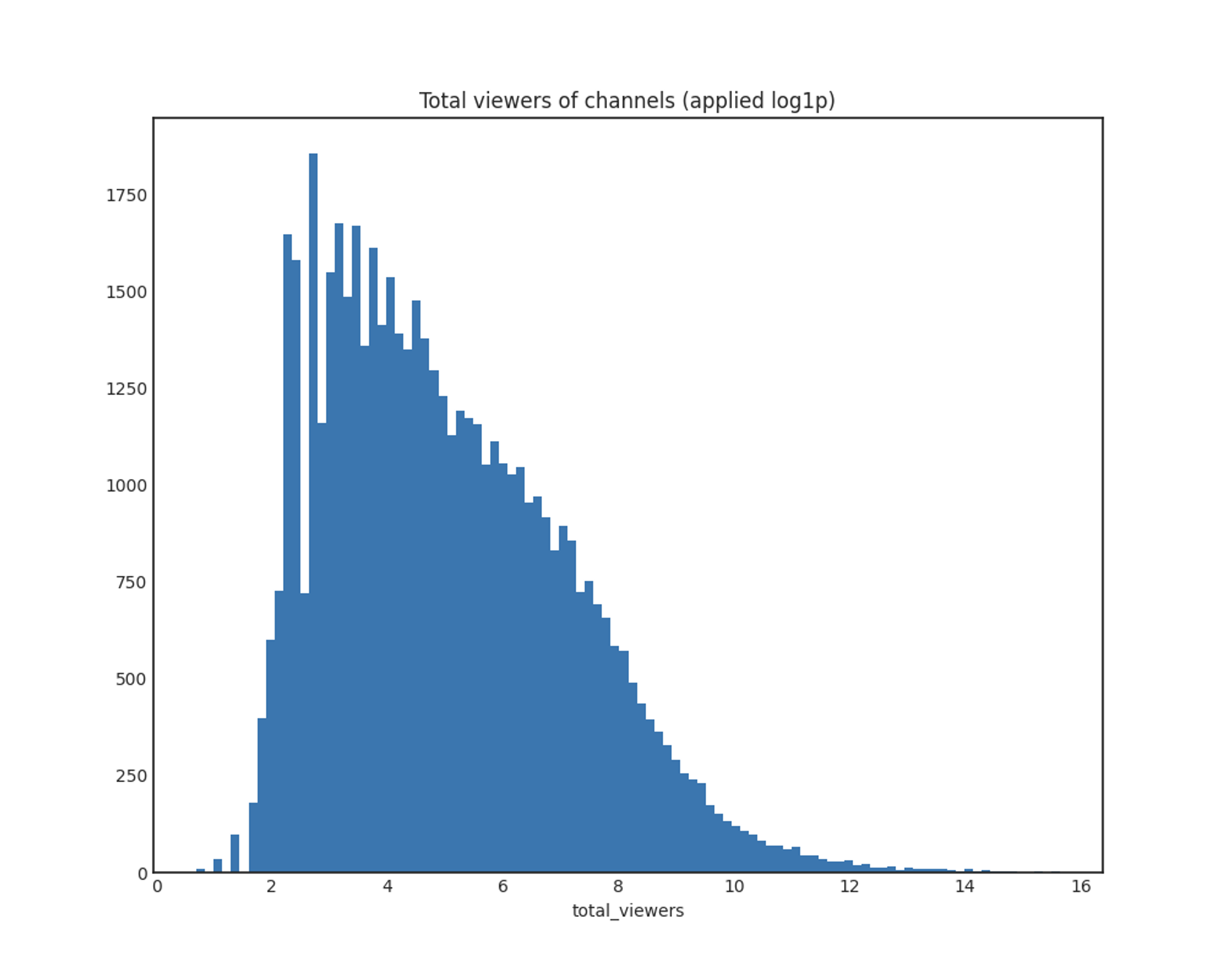
x축: 총 시청자 수
y축: 채널 개수
total_viewers도 마찬가지로 log1p 적용 결과 전체적으로 정규분포를 따릅니다.
total_chats
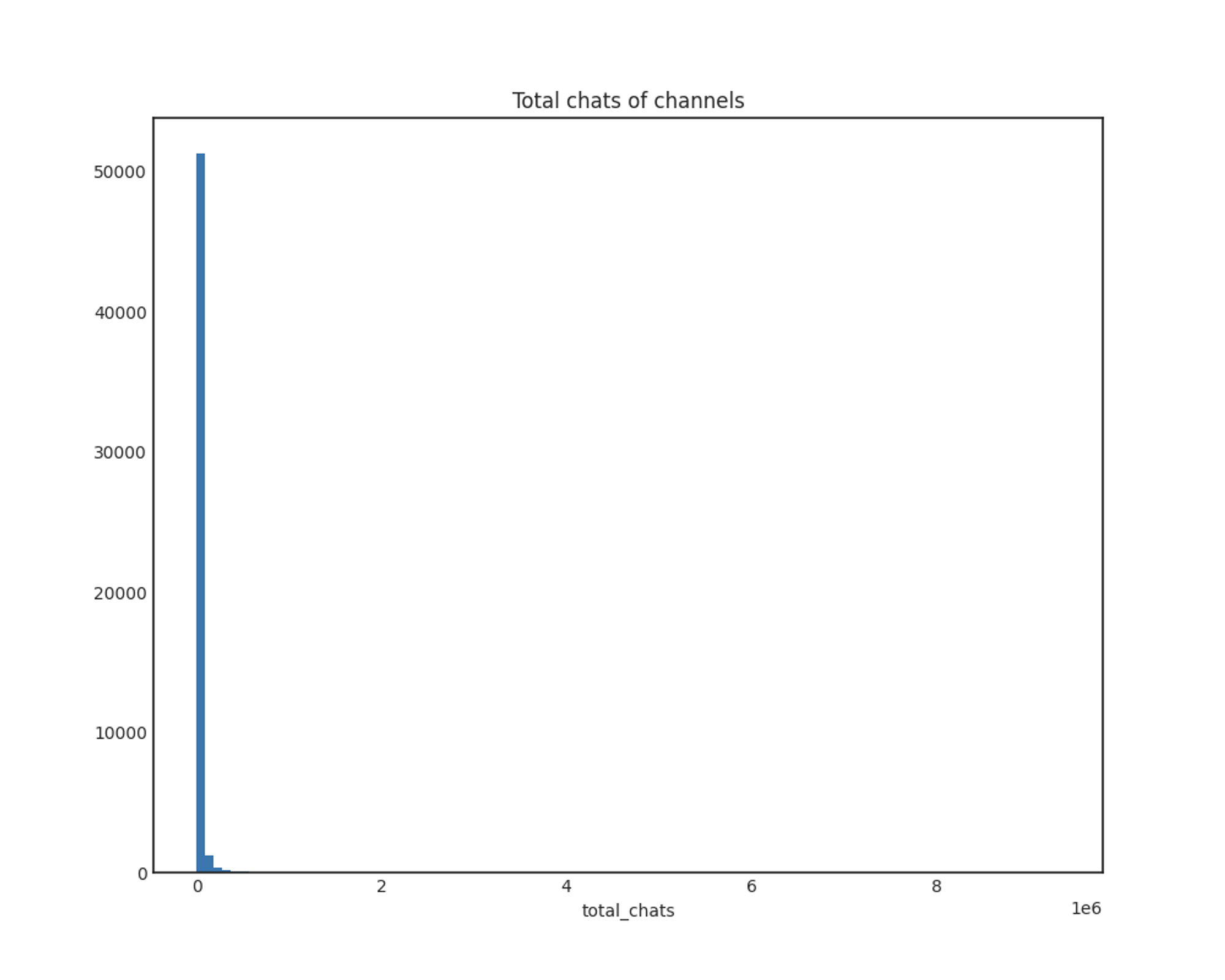
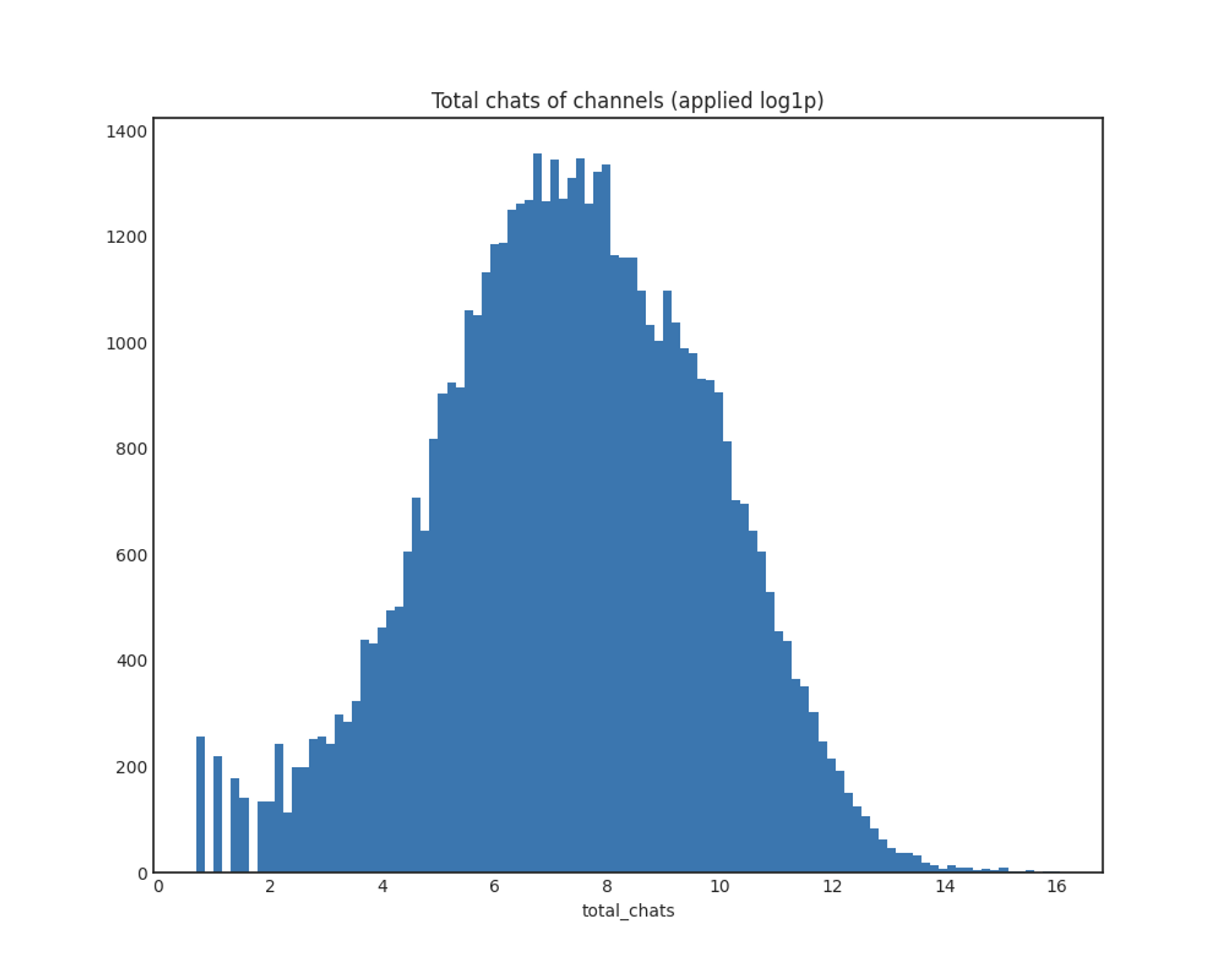
x축: 받은 총 채팅 개수
y축: 채널 개수
마찬가지로, log1p 함수를 적용한 결과 전체적으로 정규분포를 따릅니다.
이 역시 log1p 그래프에서 앞부분의 채팅이 비정상적으로 적은 방송들에 유의해야 할 것 같은데, 특히 방송 시간은 긴데 채팅이 적은 경우를 유심히 살펴볼 예정입니다. 방송 시간이 짧고 채팅도 적은 경우라면 상관없지만, 방송 시간이 길지만 채팅이 적은 경우라면 의심스러운 방송일 확률이 높다고 생각했습니다.
game_null_duration
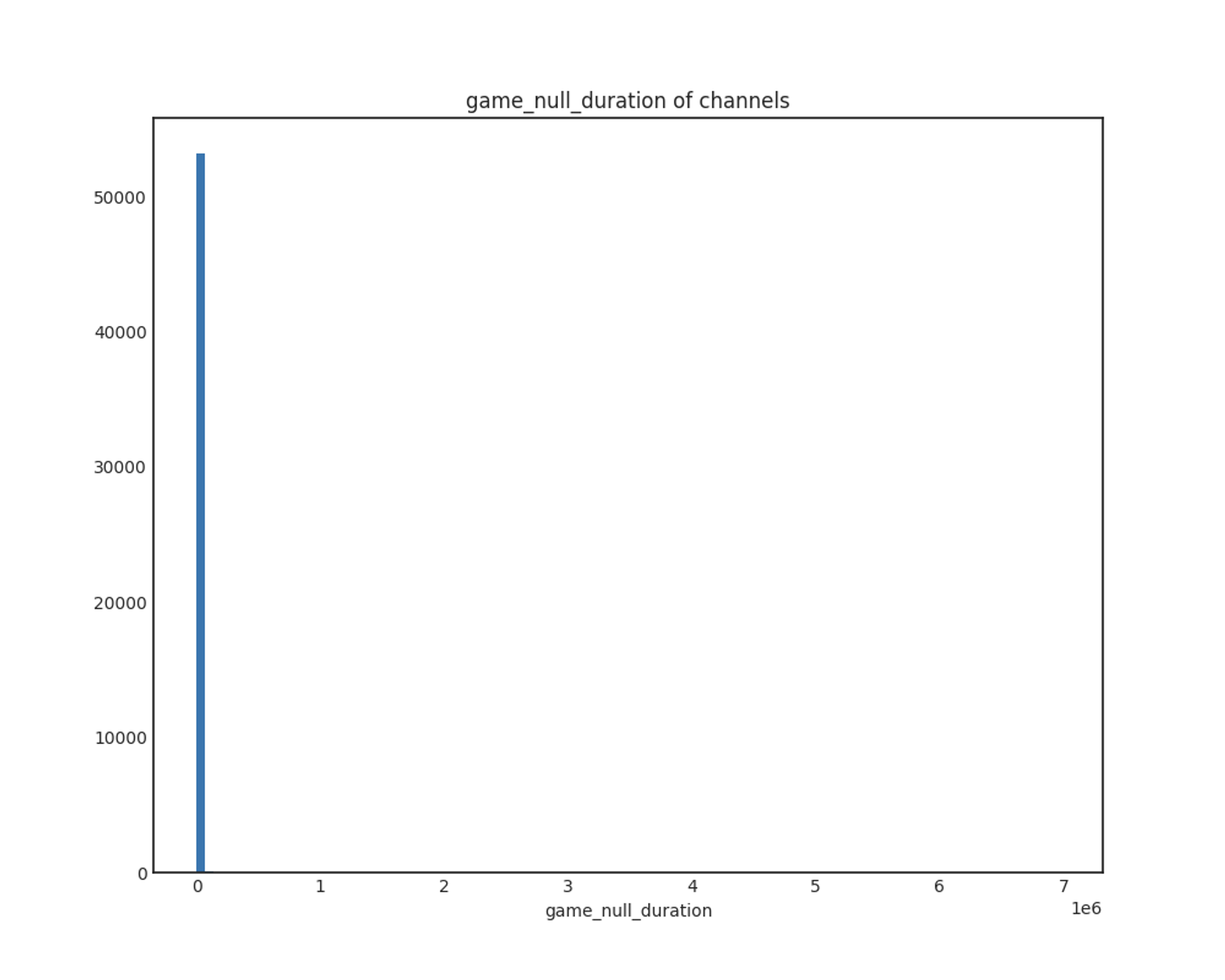
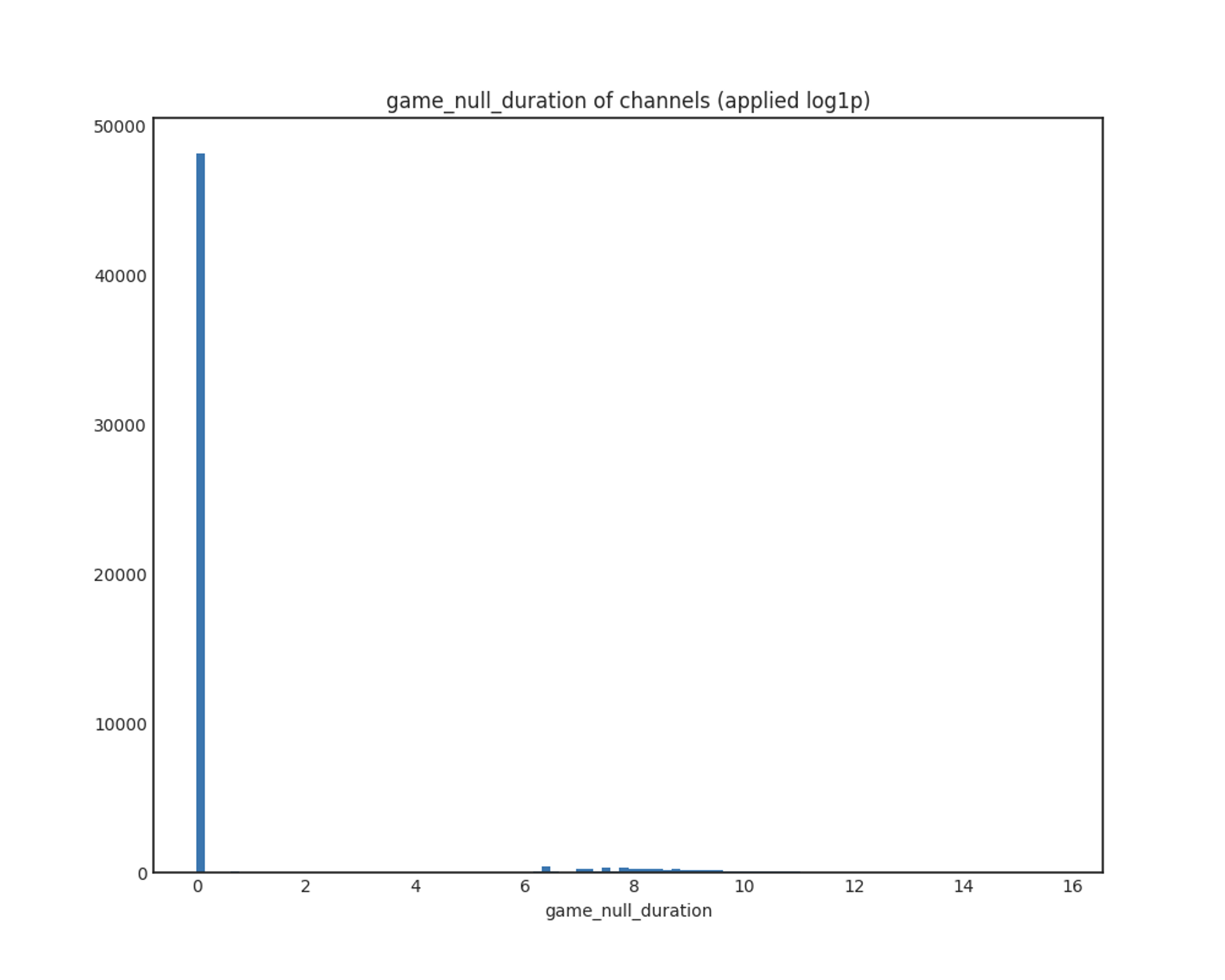
x축: 게임이 null인 상태로 방송한 시간(초)
y축: 채널 개수
유의미한 결과를 찾을 수 없었습니다. game이 null인 채로 오래 방송하는 채널은 극히 일부인 것으로 보입니다.
변수 간 상관관계 확인
Scatter plot으로 두 변수 간의 상관관계를 확인하였습니다.
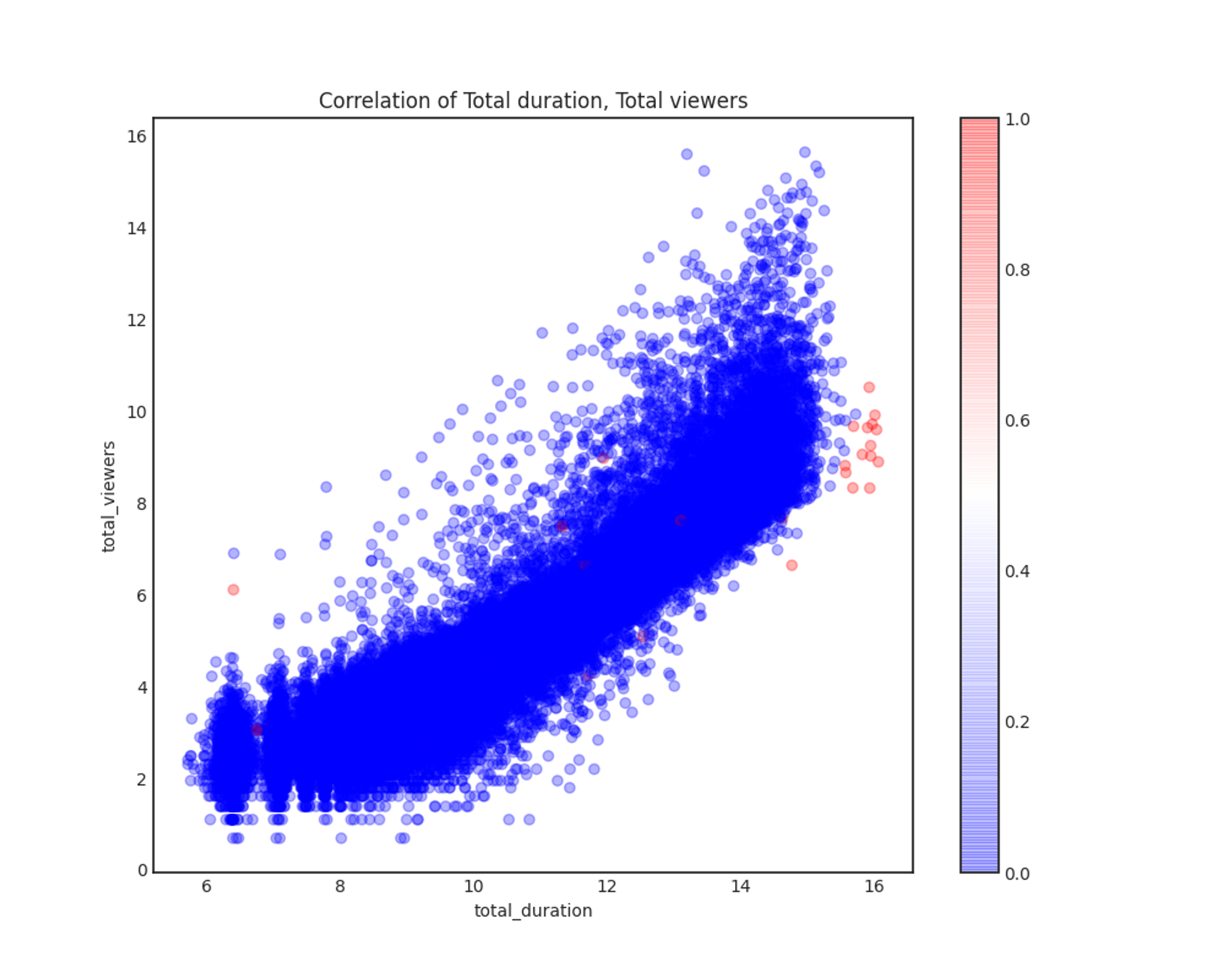
Correlation of Total duration, Total viewers
total_duration과 total_viewers는 예상했던 대로 linear 관계를 보입니다. 이 중에서 빨간색으로 표기한 점들이 일차적으로 레이블링한 부적합 방송들로, 대체적으로 total_duration이 긴 곳에 분포하지만 별다른 특징은 찾을 수 없었습니다.
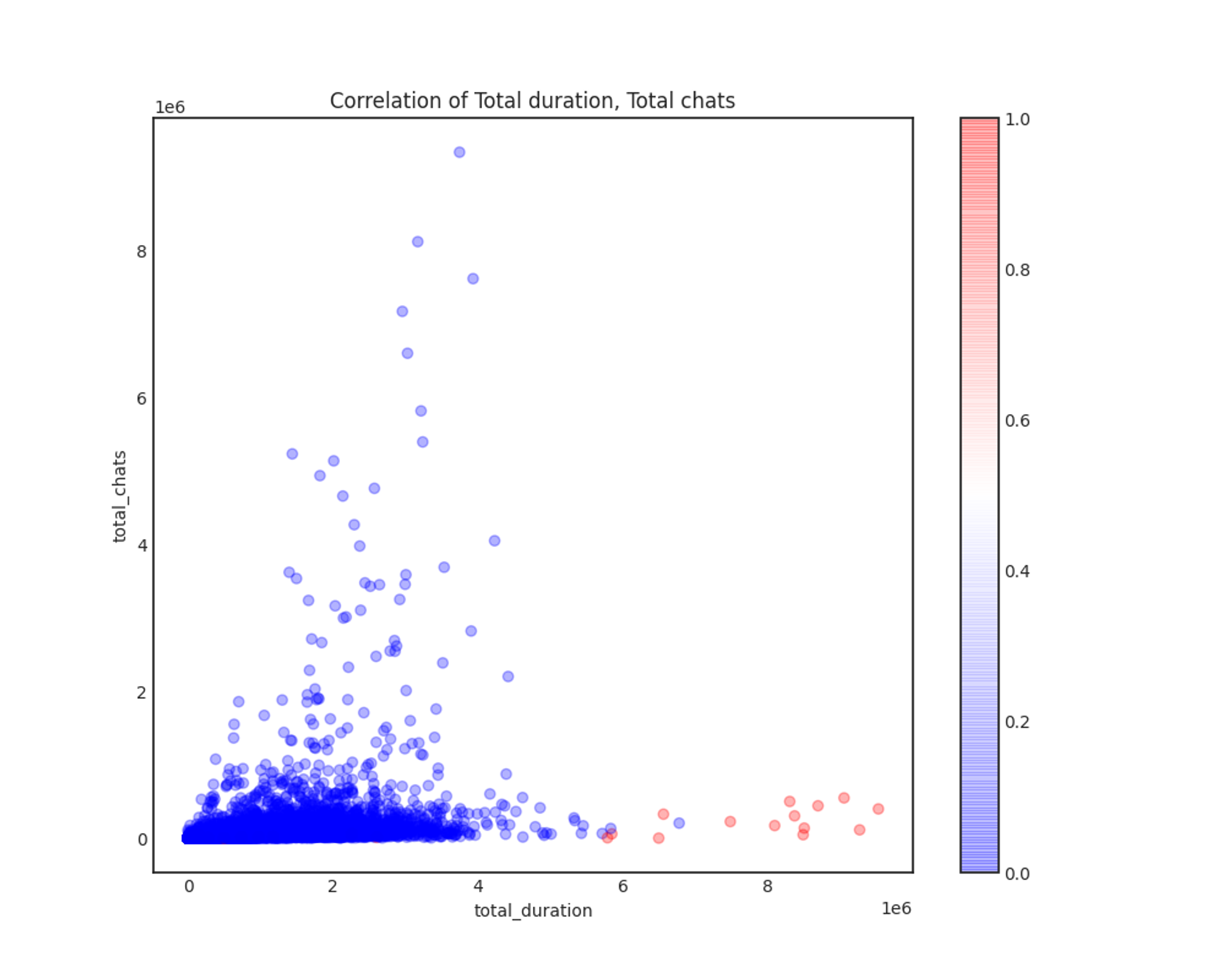
Correlation of Total duration, Total chats
total_duration과 total_chats의 상관관계에서는 조금 눈여겨볼만한 점들이 있었습니다.
우선, 총 방송 길이가 일정 수준을 넘어가면 더 이상 채팅 수가 그에 따라 증가하지 않는다는 것입니다. 그리고 총 방송 길이가 일정 수준 이상인 방송들의 경우 illegal이 1로 레이블링된 경우가 대부분이었습니다. 이는 "부적합 방송들의 경우 홍보 문구나 불법 정보를 띄워놓고 계속 방송하며, 채팅은 별로 없을 것"이라는 가설과 일치합니다.
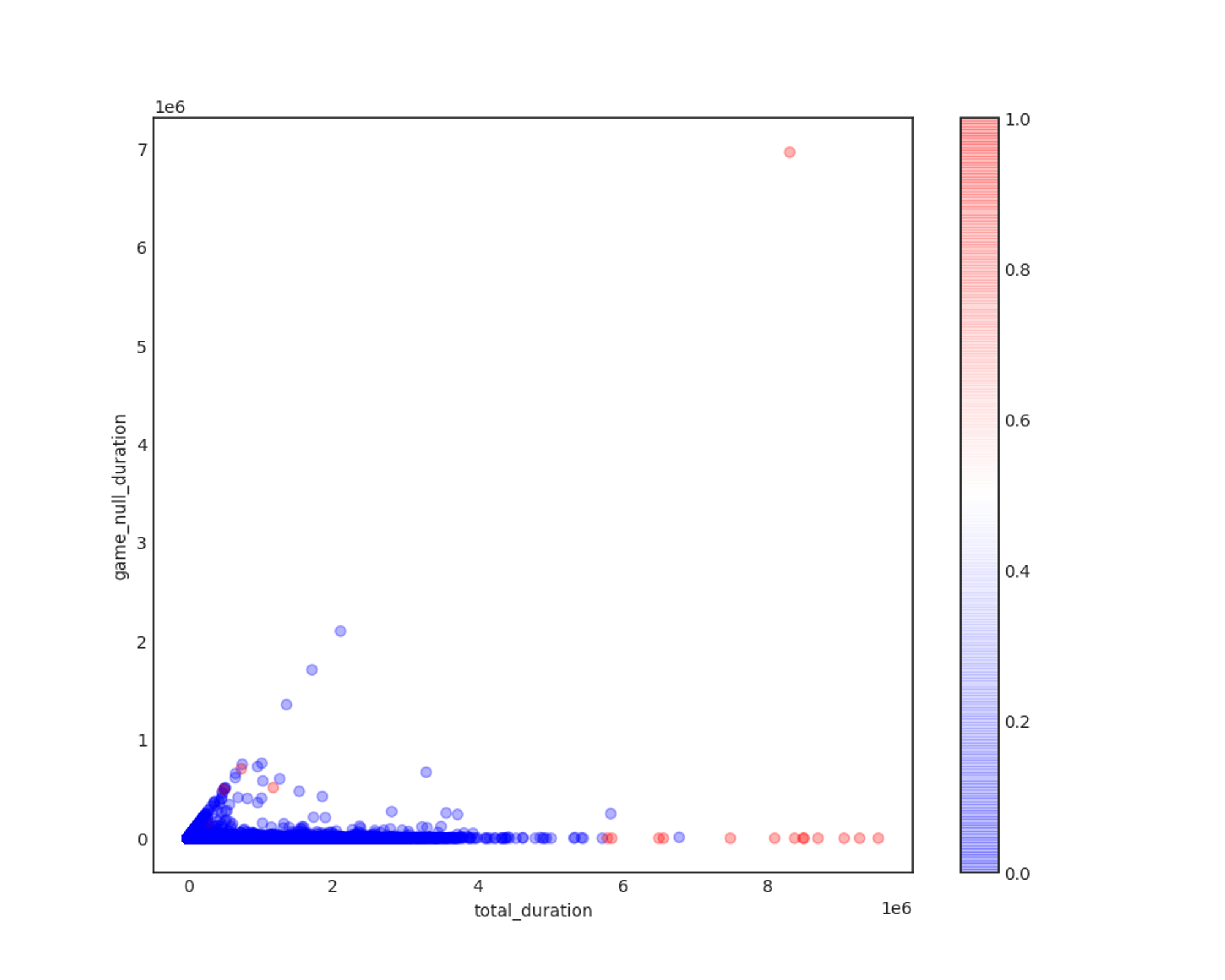
Correlation of Total duration, game_null_duration
game_null_duration의 경우 그렇게 유의미한 결론을 내리지 못했습니다. 예상했던 것과 달리, 게임이 null인 채로 방송하는 경우가 극소수이며, 그 중에서도 부적합 방송을 걸러내려면 다른 피쳐가 필요할 것이라 생각했습니다.
이와 달리, total_duration, total_viewers, total_chats 세 피쳐는 유의미하게 사용될 수 있을 것이라 판단했습니다.
머신러닝 모델 생성 및 성능 비교
PyCaret에서는 Feature Normalization, Transformation, PCA, Oversampling 등의 옵션들을 기본으로 제공하며, 학습 데이터/테스트 데이터의 분리 또한 자동으로 수행합니다.
총 53378건의 채널 데이터 중 70%인 37364건을 학습 데이터, 16014건을 테스트 데이터로 사용하였습니다. 기타 사용한 옵션은 다음과 같습니다.
•
◦
성공적인 머신러닝 모델 생성 및 추론을 위해서는 수치형 input features에 대해 데이터 정규화 작업이 필수적입니다. 여러 정규화 방법이 있지만, 상대적으로 Outlier에 덜 민감한 Z-score Normalization을 택했습니다.
•
SMOTE Oversampling을 이용해 레이블링된 데이터가 적다는 과제의 고질적인 문제를 해결하였습니다.
◦
비대칭 데이터(Imbalanced data) 문제라고도 하는 이 문제는 보통 상대적으로 적게 레이블링된 데이터를 늘리는 Oversampling 또는 상대적으로 많이 레이블링된 데이터를 줄이는 Undersampling으로 해결할 수 있습니다.
◦
실험 결과 Undersampling보다 Oversampling이 훨씬 좋은 성능을 보였고, Oversampling을 사용하지 않았을 때보다 사용했을 때가 좋은 성능을 보였습니다.
PyCaret의 compare_models 메소드를 이용해 손쉽게 여러 모델들의 성능을 비교할 수 있습니다.
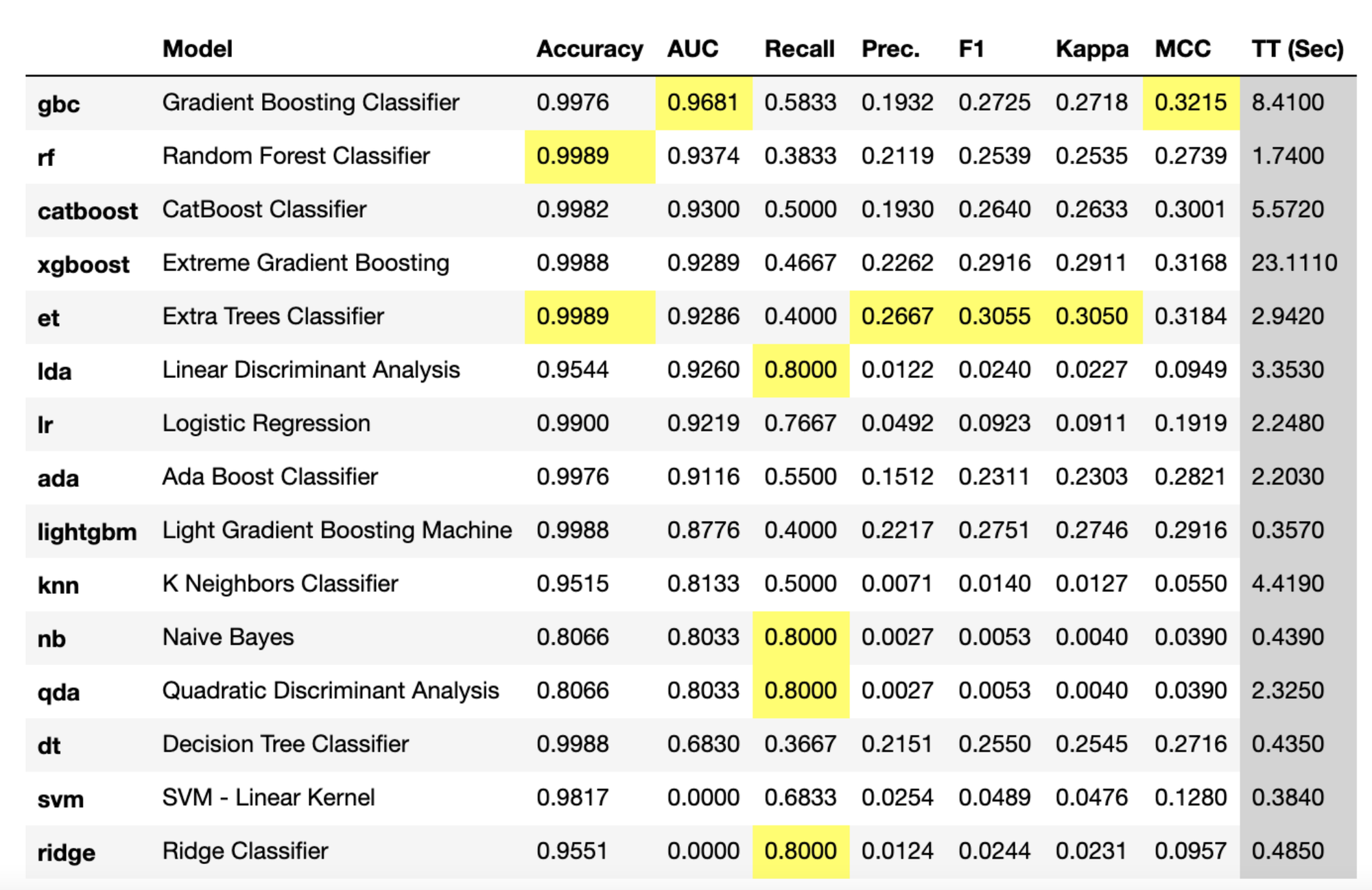
compare_models 메소드로 사용 가능한 모든 모델의 train 성능을 ROC-AUC 점수 기준으로 출력한 모습입니다. 대체적으로 트리 기반 Classifier들과 앙상블 모델들이 좋은 성능을 보이는 것을 볼 수 있습니다.
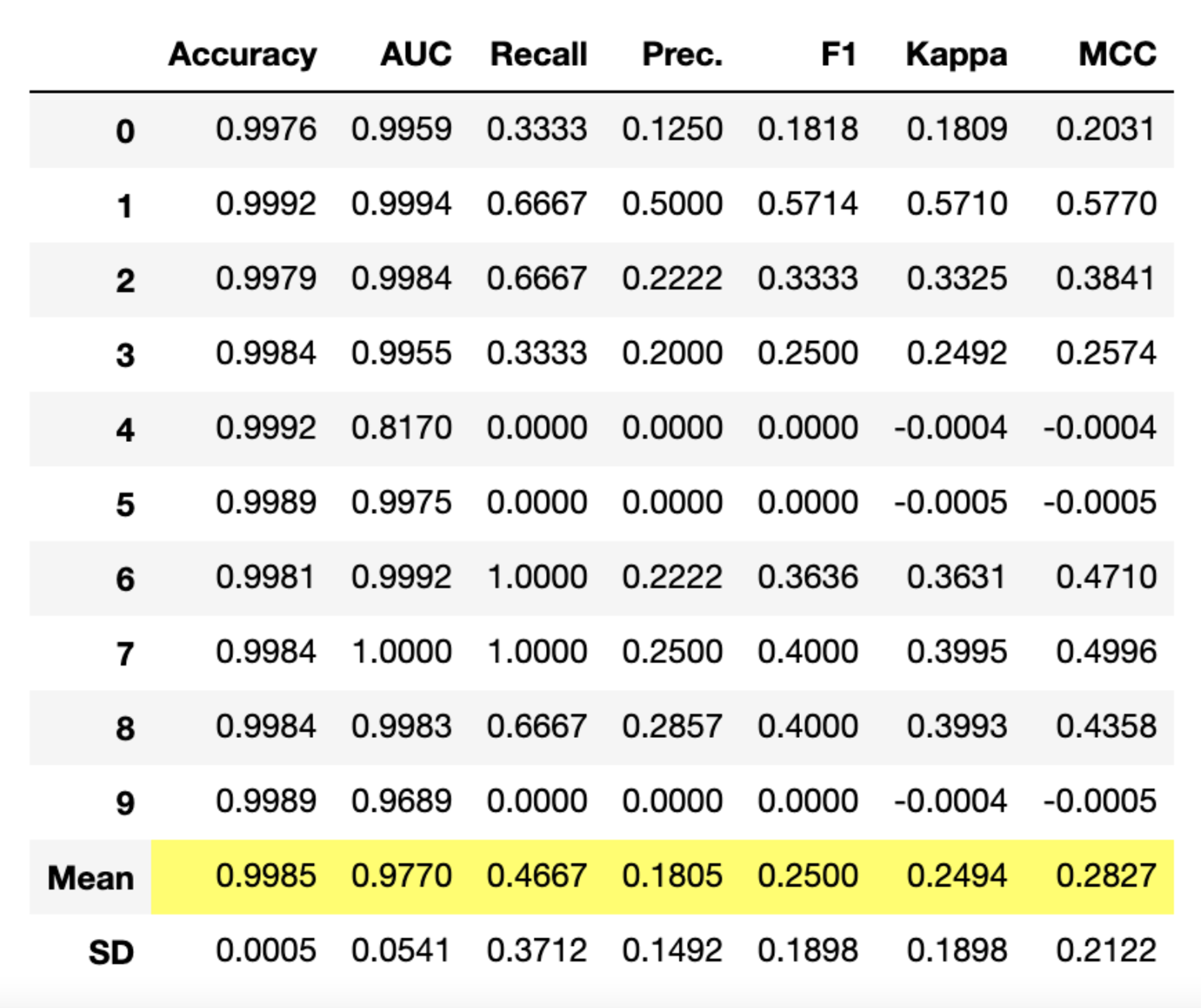
ROC-AUC 기준 상위 5개 모델을 선택하여 Blending한 모델을 생성합니다. 이 과정은 Soft Voting이라고도 불리며, 각 모델별로 예측한 값의 평균을 예측값으로 사용하는 모델을 생성합니다.
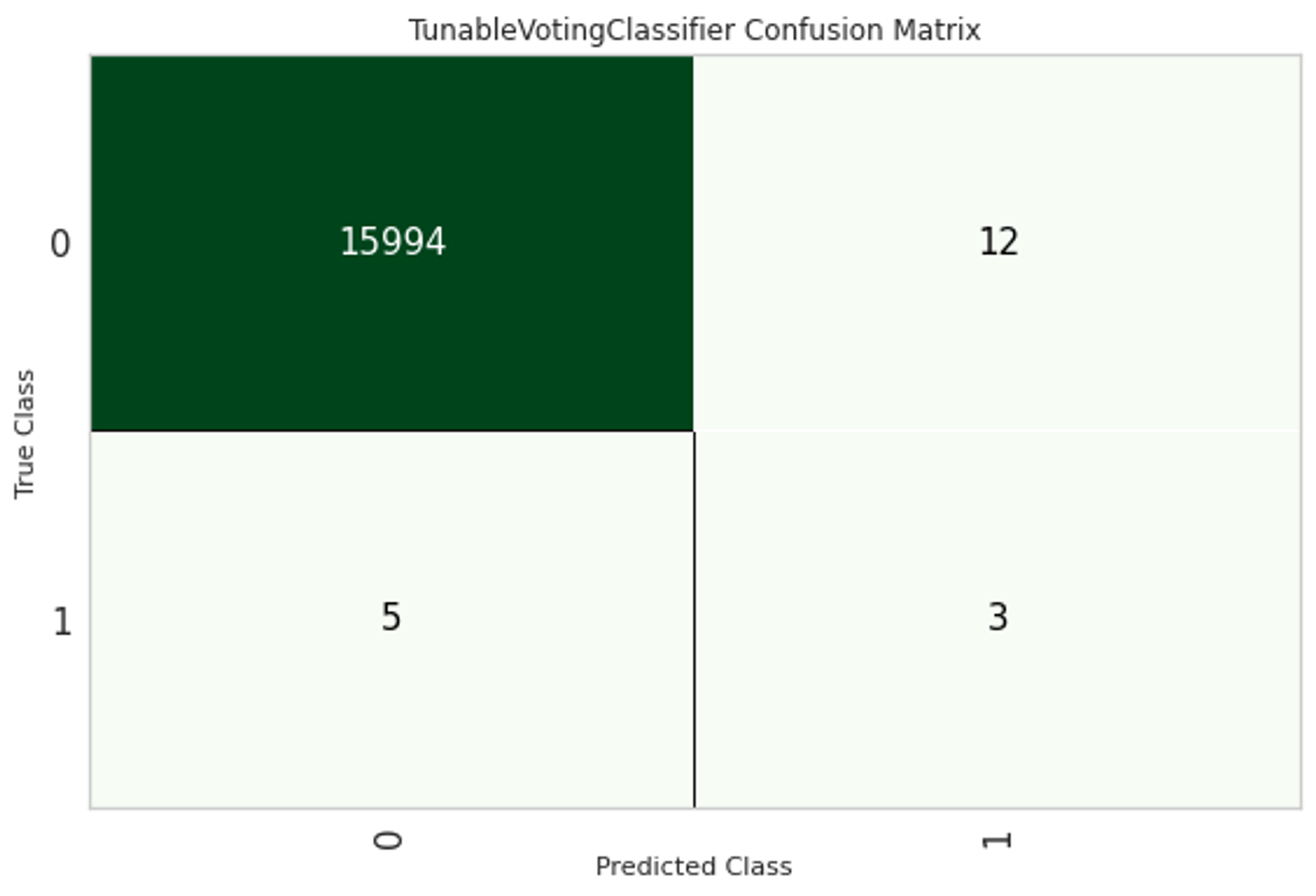
해당 모델의 Confusion Matrix입니다. 테스트 데이터 16014건 중 15997건이 정상적으로 판별되었고, 잘못 판별된 경우는 다음과 같습니다.
•
FN(False Negative, 실제 레이블은 1이지만 0으로 잘못 예측한 경우): 5건
•
FP(False Positive, 실제 레이블은 0이지만 1으로 잘못 예측한 경우): 12건
우리 과제는 "부적합 스트리머 판별"이며, 과제의 배경과 특성을 고려해보았을 때 실제로 부적합 스트리머인데도 부적합 스트리머로 분류되지 않는 경우를 줄이는 것이 (부적합 스트리머가 아닌 스트리머들이 부적합으로 분류되는 것보다) 더 중요합니다. 부적합 스트리머들이 추천 리스트에 들어오는 리스크와, 적합 스트리머들이 추천 리스트에 들어오지 않는 리스크를 비교해보았을 때 전자의 리스크가 더 크다고 판단되기 때문입니다.
즉, 우리 과제는 FN을 줄이는 것이 우선이고, Recall이 중요한 케이스임을 확인했습니다. 그렇다고 하여 Recall을 Metric으로 선정하지는 않았습니다.
이진 분류에서 Precision과 Recall 어느 한 쪽에만 치우쳐서 성능을 개선하는 것은 바람직하지 못합니다. 그렇다고 custom metric을 정의하기에는 이를 수학적으로 정의하고 증명하는 데에 너무 오랜 시간이 걸릴 것으로 예상했습니다.
이러한 상황으로 종합적으로 고려했을 때, 우수한 모델을 가장 잘 나타내는 Metric은 결국 Precision과 Recall을 모두 잘 나타내는 ROC-AUC이고, 이를 기준으로 모델 훈련 및 검증셋 평가를 진행하고 나중에 추론 결과에서 predict_proba threshold를 조절하는 것이 바람직하다고 판단했습니다.
방송 제목을 피쳐에 이용하기
이번에는 지금까지 사용하지 않았던 방송 제목(Segment의 status 칼럼)을 피쳐로 사용하여 분석을 진행해 보겠습니다. 방송 제목은 비정형 텍스트로, 단순한 카테고리형 변수로 보아서는 안 되며 데이터프레임에 피쳐로 포함하기 전에 추가적인 처리가 필요합니다.
머신러닝 알고리즘은 숫자형의 피쳐 기반 데이터만 입력받을 수 있기 때문에, 텍스트 데이터를 머신러닝에 적용하기 위해서는 비정형 텍스트 데이터를 어떻게 피쳐 형태로 추출하고 추출된 피쳐에 의미 있는 값을 부여하는가 하는 것이 매우 중요한 요소입니다.
이를 위해 텍스트의 각 단어를 벡터값으로 표현하여 텍스트를 벡터형 피쳐로 변환할 수 있는데, 이를 Feature Vectorization(Text Vectorization)이라 합니다. Feature Vectorization에는 다양한 방법이 있는데, 우리 과제에서는 일반적으로 문서 내에 텍스트가 많고, 많은 문서를 가지는 텍스트 분석에서 더 좋은 예측 결과를 낸다고 알려진 TF-IDF Vectorization 방법을 사용하겠습니다.
우선 방송 제목에 대해 클렌징 작업을 먼저 진행했습니다. 방송 제목에는 텍스트 분석에 사용할 수 없는 특수문자, 이모지 등이 포함되어 있으며, 텍스트 분석을 위해서는 이들을 먼저 제거하고 한글, 영문, 숫자만 남겨야 합니다.
def clean_text(text):
text = text.replace(".", " ").strip()
text = text.replace("·", " ").strip()
pattern = '[^ ㄱ-ㅣ가-힣|0-9|a-zA-Z]+'
text = re.sub(pattern=pattern, repl='', string=text)
return text
Python
복사
또한, 편의를 위해 텍스트 벡터화에는 단어의 길이가 2 이상인 일반명사(NNG), 고유명사(NNP), 외국어(SL)만을 사용하기로 했습니다. 이를 위해 텍스트 내의 단어들을 품사 태깅하는 작업이 필요했는데, 한국어 자연어 처리를 위해 KoNLPy 패키지와 이에 포함된 Mecab 형태소 분석기를 이용하였습니다.
def get_nouns(tokenizer, sentence):
tagged = tokenizer.pos(sentence)
nouns = [s for s, t in tagged if t in ['SL', 'NNG', 'NNP'] and len(s) > 1]
return nouns
def tokenize(sent):
tokenizer = Mecab()
sentence = clean_text(sent.replace('\n', '').strip())
return ' '.join(get_nouns(tokenizer, sentence))
Python
복사
from konlpy.tag import Mecab
tokenized = df['status'].apply(lambda x: tokenize(x))
Python
복사
문장을 단어별로 하나씩 토큰화할 때 생기는 문제는 문맥적인 의미가 무시된다는 것입니다. 문맥적인 의미를 이용하고자, 연속된 n개의 단어를 하나의 토큰 단위로 분리해 내는 n-gram을 사용했습니다. TfidfVectorizer의 파라미터로 ngram_range=(1, 3)을 지정하여 n-gram을 사용하도록 했습니다.
from sklearn.feature_extraction.text import TfidfVectorizer
vect = TfidfVectorizer(ngram_range=(1,3), min_df=2, sublinear_tf=True)
X = vect.fit_transform(tokenized)
vectorized = pd.DataFrame(X.toarray(), columns=['status_' + x for x in vect.get_feature_names()])
Python
복사
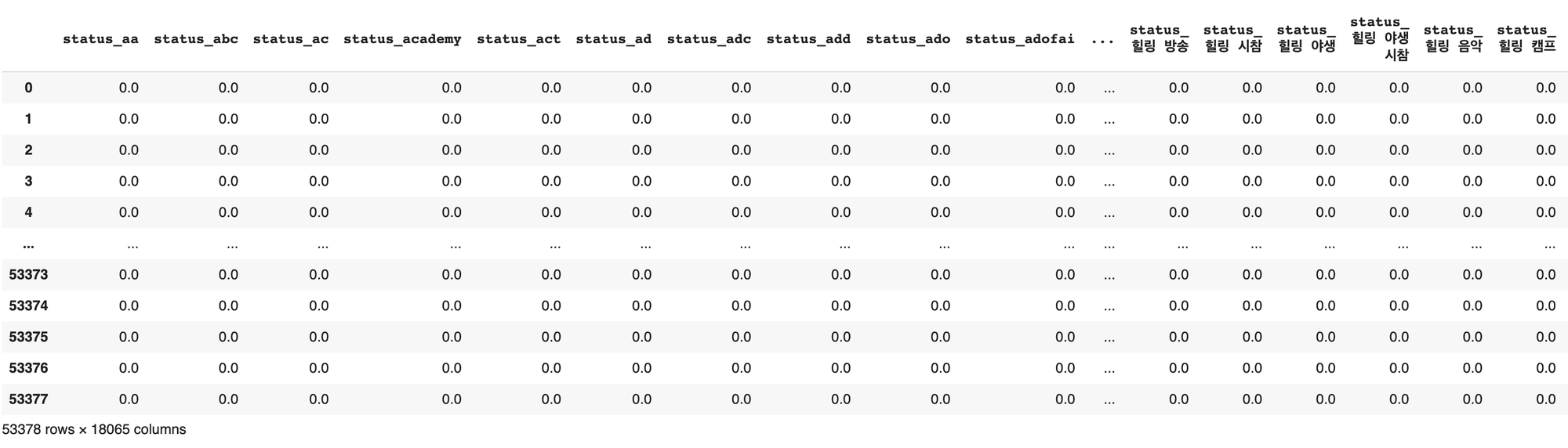
벡터화가 완료된 텍스트 데이터프레임은 총 18065개의 칼럼을 가지는 것을 볼 수 있습니다.
XGBoost 모델 생성 및 추론
새로 추가한 방송 제목 피쳐를 이용해 다시 모델을 생성하고, 실제 데이터로 추론까지 진행해 보겠습니다.
여기서도 PyCaret을 이용하려 했으나, 텍스트 피쳐로 인해 칼럼 수가 급격하게 늘어났기 때문에 메모리 문제가 계속해서 발생하여 정상적인 진행이 어려웠습니다. 따라서 PyCaret 사용을 포기하고, 가장 안정적인 성능을 보여준 XGBoost(XGBClassifier) 모델을 직접 작성하기로 하였습니다. 또한, PyCaret에서 사용했던 Normalization, SMOTE 등의 방법들도 모두 다시 작성하였습니다.
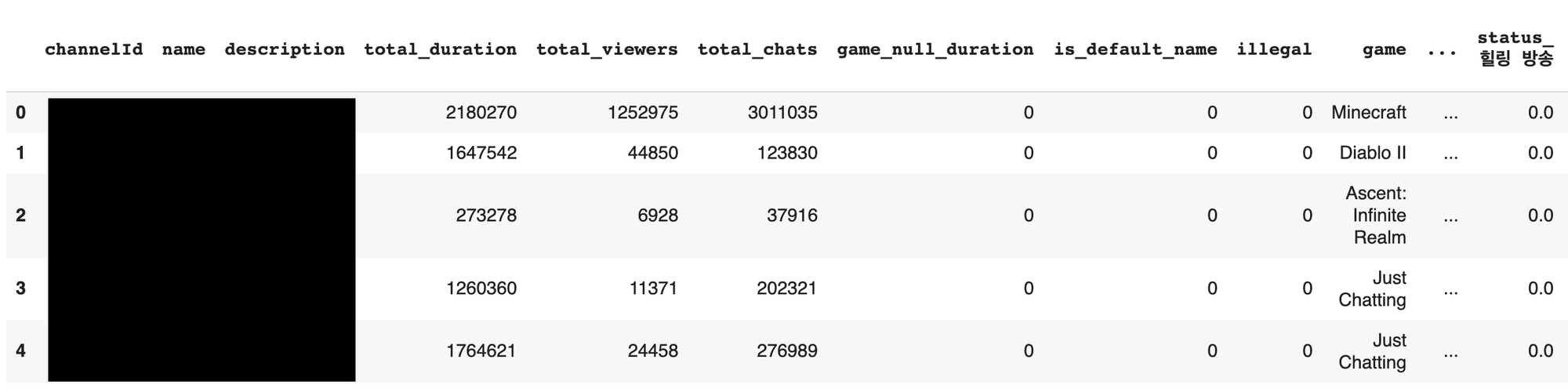
기존의 데이터프레임에 방송 제목 피쳐 데이터프레임을 concat하여 새로운 데이터프레임을 생성합니다. 데이터프레임의 shape는 (53378, 18076)이 됩니다.
게임은 카테고리형 변수이므로, 이를 적절히 처리해야 합니다. 카테고리형 변수를 수치형 변수로 바꾸는 방법에는 여러 방법이 있지만, 여기서는 더미 변수를 생성하는 방법을 선택했습니다.
game_dummies = pd.get_dummies(df['game'], prefix='game')
df = df.drop(['game'], axis=1)
df = pd.concat([df, game_dummies], axis=1)
Python
복사
수치형 피쳐들을 log1p 함수를 이용해 Log normalization한 후, 분석에 필요없는 칼럼들을 분리했습니다. 그리고, scikit-learn의 train_test_split 메소드를 이용해 학습 데이터셋과 테스트 데이터셋을 분리했습니다. 학습 데이터셋과 테스트 데이터셋이 분리될 때 레이블이 불균형하게 분리되는 것을 막기 위해 stratify 옵션을 사용했습니다.
df['total_duration'] = np.log1p(df['total_duration'])
df['total_viewers'] = np.log1p(df['total_viewers'])
df['total_chats'] = np.log1p(df['total_chats'])
df = df.drop(['channelId', 'name', 'description', 'status'], axis=1)
Python
복사
X = df.drop(['illegal'], axis=1)
y = df['illegal']
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y)
Python
복사
from imblearn.over_sampling import SMOTE
smote = SMOTE(n_jobs=-1)
X_train_over, y_train_over = smote.fit_sample(X_train, y_train)
Python
복사
데이터 준비가 완료되었고, 이제는 머신러닝 모델을 생성할 차례입니다.
원래는 Grid search를 통해 XGBClassifier의 최적의 파라미터를 찾고 이를 적용하고자 했으나, 이조차도 메모리 초과로 Segmentation Fault가 발생하는 관계로 적절한 파라미터를 지정해 모델을 생성하고 학습했습니다.
from xgboost import XGBClassifier
xgb = XGBClassifier(
max_depth=8,
min_child_weight=3,
gamma=0,
nthread=-1,
colsample_bytree=0.5,
colsample_bylevel=0.9,
n_estimators=20000,
random_state=2
)
Python
복사
Metric으로는 ROC-AUC를 사용했고, early_stopping_rounds는 100으로 지정했습니다.
eval_set = [(X_test, y_test)]
xgb.fit(
X_train_over, y_train_over,
early_stopping_rounds=100,
eval_metric='auc',
eval_set=eval_set,
verbose=True
)
Python
복사
학습 결과, Feature importance는 다음과 같이 나타났습니다.
[('total_viewers', 742),
('total_duration', 687),
('total_chats', 674),
('status_empty', 144),
('status_방송', 62),
('is_default_name', 53),
('status_그림', 51),
('status_발리', 17),
('status_챌린지 시작', 14),
('game_Art', 10),
('game_Just Chatting', 9),
('status_주식', 9),
('status_flight', 8),
('status_챌린지', 8),
('status_폭스', 7),
('status_대한민국', 7),
('status_grinding', 6),
('status_유입', 6),
('status_시작', 6),
('status_티켓', 6),
('status_족보', 5),
('game_League of Legends', 5),
('status_시참', 4),
('status_zoom', 4),
('status_the', 4),
('status_슬롯', 3),
('status_환영', 3),
('status_이벤트 방송', 3),
('game_MapleStory', 3),
('status_발리 폭스', 3),
('game_World of Warcraft', 3),
('game_Overwatch', 3),
('status_추천 방송', 3),
('status_신입', 3),
('status_카지노 슬롯', 2),
('game_Poker', 2),
('status_족보 방송', 2),
('game_Minecraft', 2),
('status_슬롯 머신', 2),
('status_리니지', 2),
('game_Valorant', 2),
('game_Monster Hunter World', 2),
('status_경제', 1),
('status_온라인 카지노', 1),
('status_랭킹', 1),
('status_토너', 1),
("game_PLAYERUNKNOWN'S BATTLEGROUNDS", 1),
('status_가상', 1),
('status_폭스 발리', 1),
('status_온라인 카지노 슬롯', 1),
('status_투견 발리', 1),
('status_music', 1),
('game_Black Survival: Eternal Return', 1),
('status_전문가', 1),
('status_dance', 1),
('status_상위', 1),
('status_카지노 슬롯 머신', 1),
('status_게임', 1),
('status_오늘', 1),
('status_한국', 1),
('status_온라인', 1),
('status_카지노', 1)]
Python
복사
맨 처음에 알 수 있는 것은, 앞에서 생성했던 total_viewers, total_duration, total_chats 세 개의 변수가 가장 중요도가 높게 나타났다는 것입니다. 그 다음으로는 방송 제목 키워드가 많이 나타나는 것을 볼 수 있는데, 특히 '발리", "폭스", "족보 방송" 등 리니지 도박 방송을 의미하는 키워드들이 잡히는 것이 눈에 띄었고, "슬롯", "카지노" 등 일반적인 불법 방송들의 키워드 또한 피쳐로 작용한 것이 눈에 띕니다.
학습된 모델로 실제 예측까지 진행해 보았습니다. 예측은 전체 데이터프레임을 대상으로 진행했고, pred_proba값을 뽑아 0.9 이상인 데이터만 출력해 보았습니다. 결과는 다음과 같았습니다.
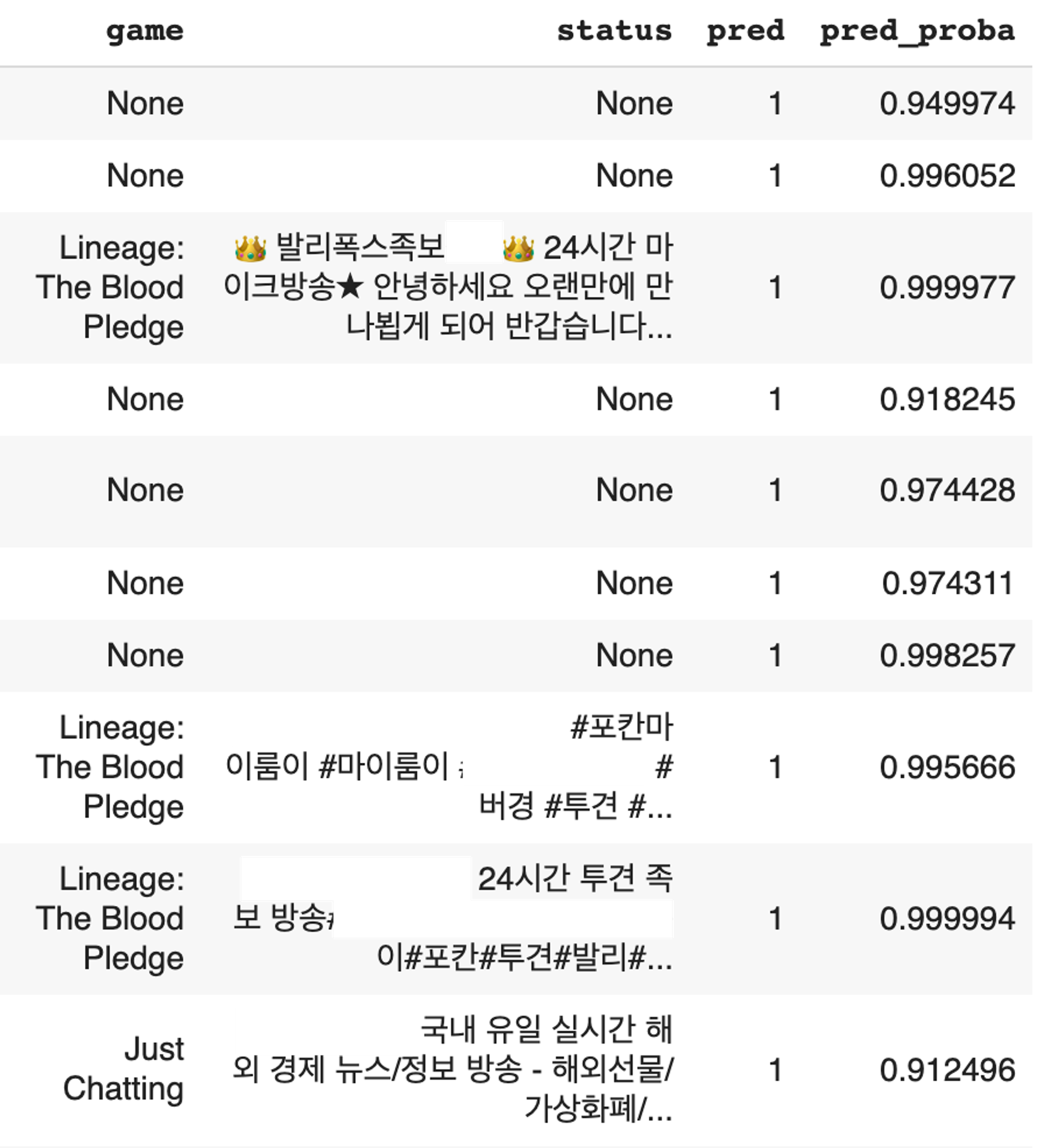
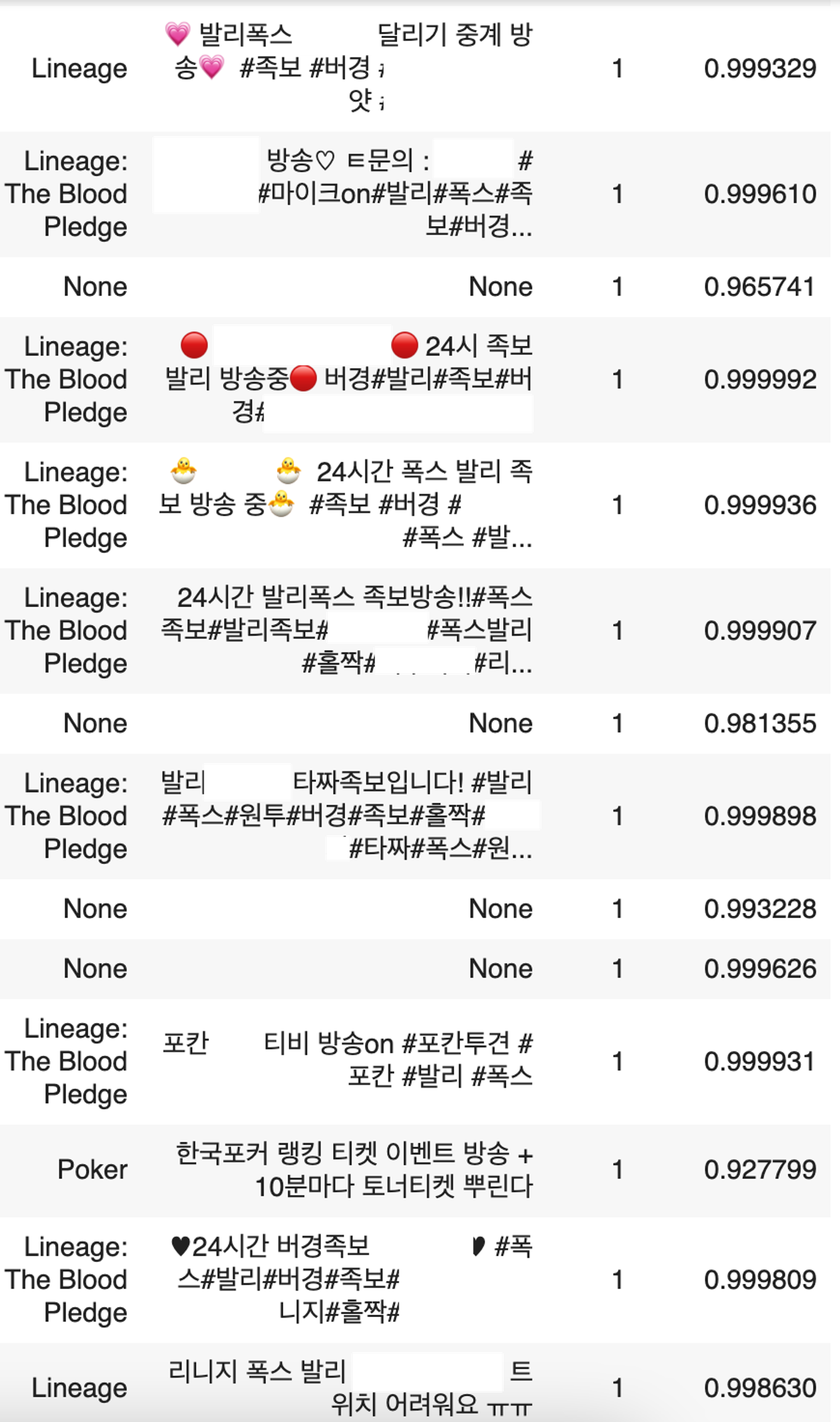
대다수의 부적합 방송들이 높은 pred_proba로 예측된 것을 확인할 수 있습니다. 심지어 게임과 방송 제목이 null인 데이터에 대해서도 대다수가 부적합 방송이었고, 계속해서 실패한 예측을 보이는 케이스는 다음과 같았습니다.
•
각종 교회 방송: 교회에서 예배 방송을 트위치로 스트리밍하는 경우가 있었는데, 계속해서 교회 방송이 부적합 스트리머로 예측되었습니다. 이 경우 방송 시간은 길지만 채팅 수가 적다는 특징이 부적합 방송과 부합한 것으로 예측됩니다.
•
시청자가 별로 없는, 평균 방송 시간이 긴 방송: 이 경우 역시 마찬가지로, 평범한 개인 방송임에도 평균 방송 시간이 길지만 시청자나 채팅이 별로 없었던 방송들이 있었습니다. 이들 역시 Input feature의 한계로 부적합 스트리머로 집계될 수밖에 없었습니다.
이렇게 pred_proba가 일정 수준 이상인 데이터들을 추려내어 수작업으로 부적합 방송인지 아닌지를 직접 체크하여 레이블링했고, 이 과정을 더 이상 부적합 스트리머가 하나도 나오지 않을 때까지 반복하였습니다.
결론
이 프로젝트에서는 부적합 스트리머 판정을 단순한 이진 분류 문제로 보고 이를 머신러닝으로 풀 수 있음을 보였습니다. 특히 아무것도 없는 데이터셋에서 시작하여 수작업 레이블링 후 모델을 돌려 레이블을 늘려 나가고, imbalanced data 상황에서 어떻게 문제를 해결하였는지 보였습니다.
9주라는 시간은 그렇게 긴 시간이 아니었습니다. 레이블을 뽑고 다시 모델을 돌리는 Iteration이 상당히 오랜 시간을 잡아먹었으며, 메모리 부족으로 인해 모델 파라미터도 Grid search를 돌리지 못하고 적당한 최적 파라미터를 선정하였습니다. 중간중간 논리적 비약도 많았고, 데이터 부족으로 Tuning point가 많이 없었던 것이 아쉬운 점입니다.
비록 상세한 실험은 기간이 짧은 바람에 시도해보지 못했지만, 그래도 회사에서 수행하는 첫 머신러닝 프로젝트로써 중요한 포인트는 잡아서 수행했고, 앞으로 회사에서 수행하는 다른 머신러닝 프로젝트의 초석이 될 것이라 생각합니다.
회사 소개


“크리에이터들이 보다 재미있고 가치 있는 콘텐츠를 만들 수 있도록 돕습니다"
이제이엔은 트위치 후원 오버레이 플랫폼 '트윕(Twip)'과 트위치 유저 커뮤니티 '트게더(Tgd.kr)', eSports 대회 플랫폼 '배틀독(Battle.dog)'을 운영하고 있습니다.
BJ, 스트리머, 유튜버라고도 불리는 크리에이터는 인터넷 개인방송 플랫폼을 이용하여 팬들과 실시간으로 소통하고 있습니다. 이제이엔의 서비스를 이용하면 크리에이터 누구나 팬들과 상호작용할 수 있는 콘텐츠를 손쉽게 만들 수 있고 이를 통해 수익을 창출할 수 있습니다.
이제이엔은 크리에이터가 팬들과 함께 지속적으로 꾸준히 콘텐츠를 만들 수 있도록 돕는 방법을 끊임없이 고민하고 있는 열정적이고 훌륭한 사람들이 모인 곳입니다. 일과 삶의 조화를 통해 즐겁게 일하는 문화를 만들어, 회사와 직원이 함께 성장하고자 노력하고 있습니다.